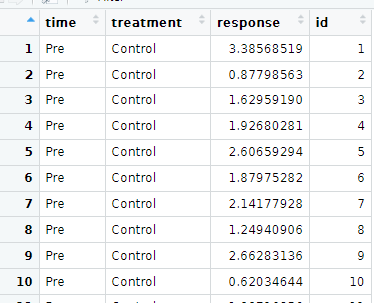
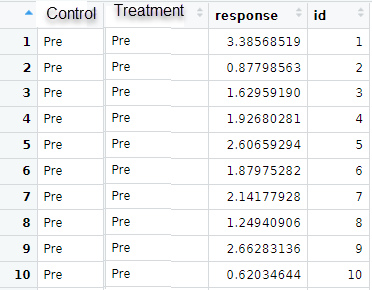
I want to pivot it somehow so I will get columns: Control - with pre and post levels in it and Treatment with pre and post levels in it. Values will go to Values column obviously.
How do I do it, please give me some advice.
Yes, this is going in good direction, but one patient could only be in either of two groups: Control or Treatment.
That looks like is placed in both simultaneously.
Yes, thank you very much (this is good), if I may ask additionally as in my first OP,
So I will have got let's say a variable Control and in it pre and post values and variable Treatment and pre and post values (words/strings) in it and additional column where numbers will be placed accordingly . Is this possible ?
what is the operation you are performing here ?
if you did it by hand, what would you be doing ?
it seems like measurments are taken, a measurement gets taken at a certain time; that time is is pre or post some known time. the measurement relates to something that was either in a treatment group or a control group. All this seems straightforward inthe first post. in what you want to achieve what is the interpretation ?
is it that yould have NA values ? where a control was Pre or Post if it was a control, but be NA if it came from a treatment record, (or vice - versa) ?
(x <- rbind(
data.frame(time = "Pre", treatment = "Control", response = rnorm(100, mean=2)),
data.frame(time = "Pre", treatment = "Treatment", response = rnorm(100, mean=1)),
data.frame(time = "Post", treatment = "Control", response = rnorm(100, mean=1)),
data.frame(time = "Post", treatment = "Treatment", response = rnorm(100, mean=3))
) |>
mutate(time = factor(time, levels = c("Pre", "Post")),
id=row_number()))
widerx <- pivot_wider(x,
names_from="treatment",
values_from = "time")
# you can use widerx
# looks at a summary of it to see if it makes sense /is what is expected
group_by(widerx,
Control,Treatment) |> summarise(n=n(),mean_response=mean(response))
Yes, thank you, this is what I expected, I will divide widerx dataframe into two dfs in order to get rid of Nas and it will be better for me to present it on the graph.