Shiny Cinnamon Words
Authors: Amy Huang
Abstract: Upload a set of documents exemplifying your writing, and this app will compare the words you use most often to words in a reference corpus -- the words that you uniquely use most frequently are your cinnamon words!
Full Description: Inspiration
The term "cinnamon word" comes from Ben Blatt's wonderful little treatise on data analysis of literature and writing, Nabokov's Favorite Word is Mauve. In the book, he shows how analytics — statistics' less committal and more creative cousin — can be used to direct us to interesting questions about writing. As the title suggests, one of his analyses focuses on the favorite words of famous authors. 'Cinnamon words' in particular are coined in reference to Ray Bradbury's love of the word cinnamon, which in turn comes from Bradbury's love of his grandmother's spice boxes. Blatt shows that we don't just have to take Bradbury's own observation for granted; according to his analysis, Ray Bradbury uses the word cinnamon 4.5 more often than it's seen in a reference.
What about those of us who haven't yet identified the deep childhood memories which define our writing? That is what I'm hoping my RShiny application, Shiny Cinnamon Words (SCW), can tell you.
The Method
Cinnamon words, as defined by Blatt, must meet the following set of requirements:
- It must be used in half an author's books
- It must be used at a rate of at least once per 100,000 words throughout an author's books
- It must not be so obscure that it's used less than once per million in the Corpus of Historical American English
- It is not a proper noun
Since the original definition of cinnamon words was intended for established authors who already have a very extensive repertoire, for the sake of all the less established writers out there, I have defined an alternate set of requirements which I use in SCW. Given a set of uploaded documents, SCW takes into account the following:
- It should be used in at least half the uploaded documents
- It should be used at rate of at least once per 100,000 words throughout the uploaded documents, which is approximately once in a novel length document
- It should not be so obscure that it does not appear in the reference corpus; the default reference corpora have already been filtered such that they won't match with words that are used less than once per million times
- It should be used at least ten times more than in the reference corpus
I say "should" instead of "must," because in SCW, these are the default settings, and there are many opportunities for customization and flexibility for you to conduct your own analysis!
Getting your Cinnamon Words
Here's the landing page for the app, which you can find on my GitHub or hosted on shinyapps.io. Click on 'Get my cinnamon words!' to get started with uploading your text files.
Then, you will be able to upload documents and select a reference corpus.
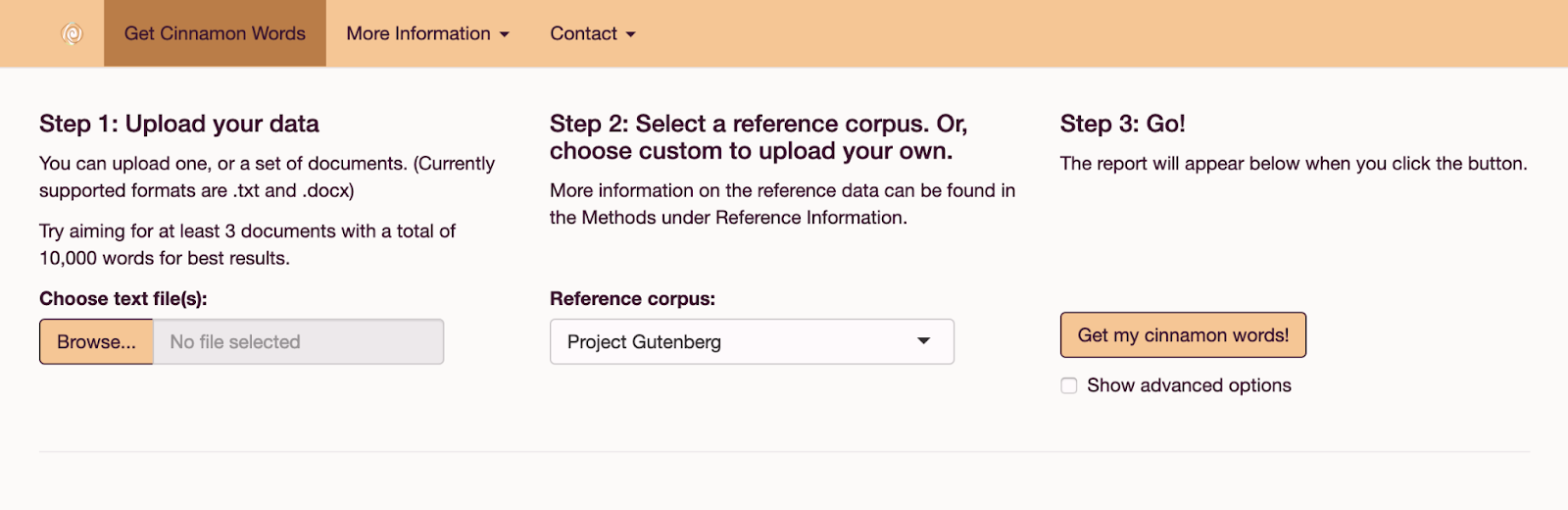
Given a set of uploaded documents, SCW will calculate the frequency at which every word appears in your document. The application also has a set of preloaded reference corpora which are used as a baseline measure of word frequencies in the English language, which it will then use to calculate a ratio of use, showing you which words in your set of uploaded documents are most frequently used compared to the reference. These are your cinnamon words!
You can also upload a text file to use as a custom reference corpus, if you so choose. Just select 'Custom' from the reference corpus drop down menu.
Here is an example using sixteen of Plato's works from Project Gutenberg, translated by Benjamin Jowett as the sample text:
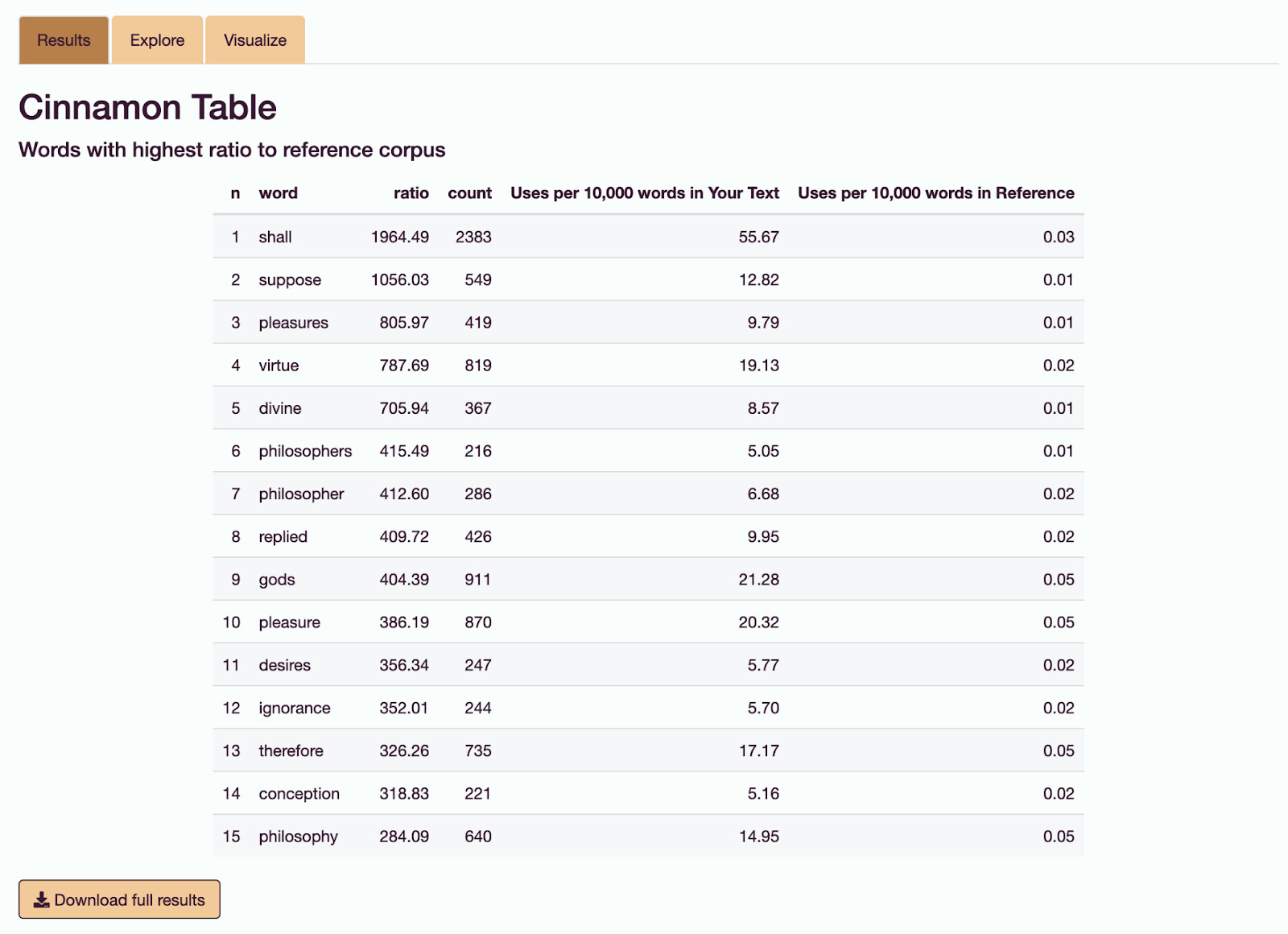
It makes sense that the philosophers are supposing quite a lot!
Further Analysis
Beyond the table of your cinnamon words, you can also go to the 'Explore' tab, which allows you to search for any word in the uploaded text, powered by the DT package in R.

In the 'Visualize' tab, you will find plots which have been generated using your uploaded data.
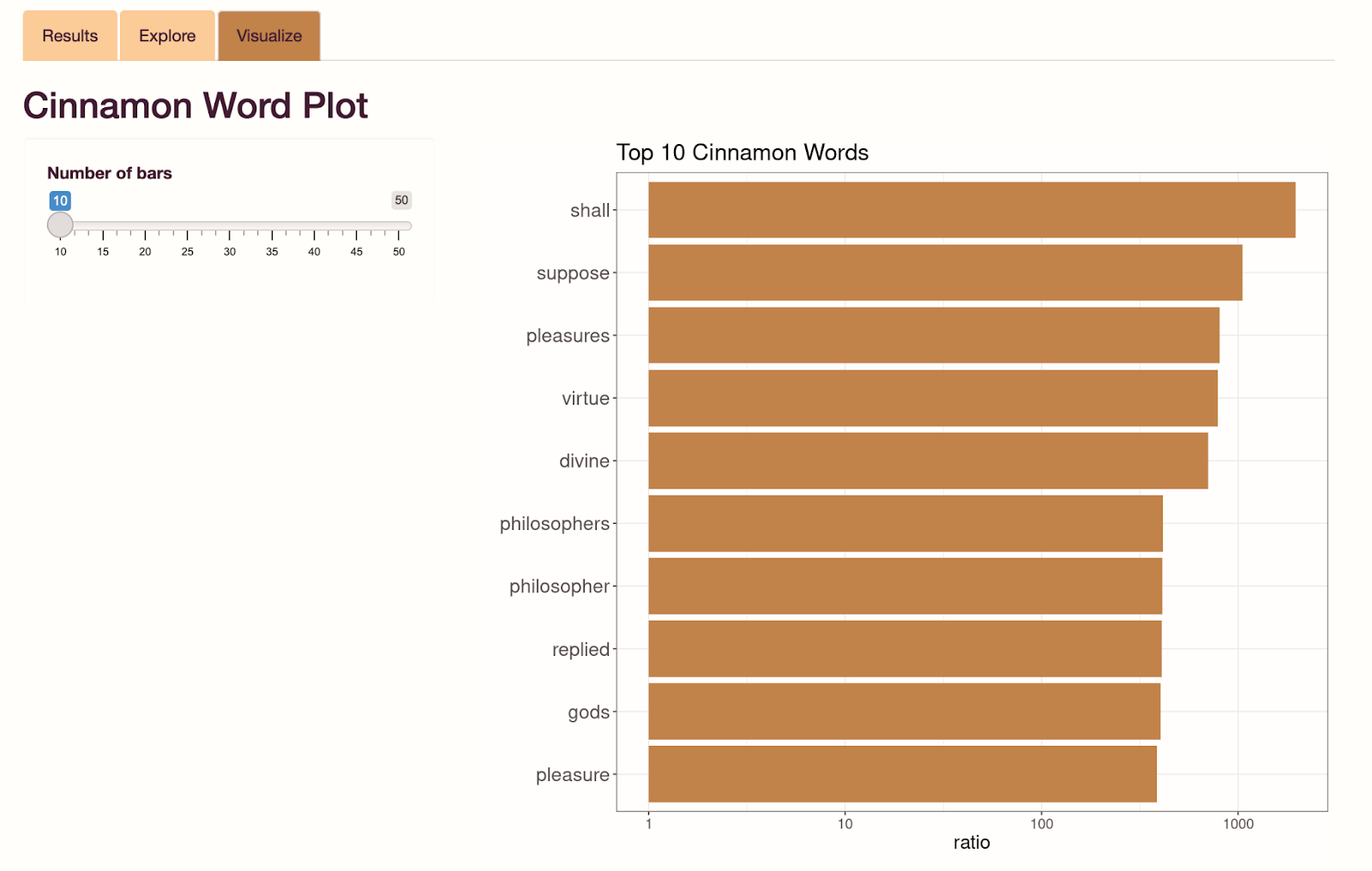
All other information you need to get started should be there on the app, so go try it out!
Citations
Blatt, Ben. Nabokov’s Favorite Word Is Mauve: What the Numbers Reveal about the Classics, Bestsellers, and Our Own Writing. First Simon&Schuster hardcover edition. New York: Simon & Schuster, 2017.
Project Gutenberg. (n.d.). Retrieved February 21, 2016, from www.gutenberg.org.
Keywords: text analysis, text, writing, word frequency, gutenbergr, textdata, DT
Shiny app: https://improbable-puffin.shinyapps.io/shiny-cinnamon-words/
Repo: https://github.com/amyh25/shiny-cinnamon-words
RStudio Cloud: Posit Cloud
Thumbnail:

Full image: