So I created a Shiny app. From a functionality standpoint, it works fine. But the issue is the load time. There are times where it takes several minutes just to load the page. Other users in my organization have reported that it just doesn't load at all. When I test things locally, it works fine. But the issues arise once it gets deployed to my server. If it helps, here is how I currently have the settings at:
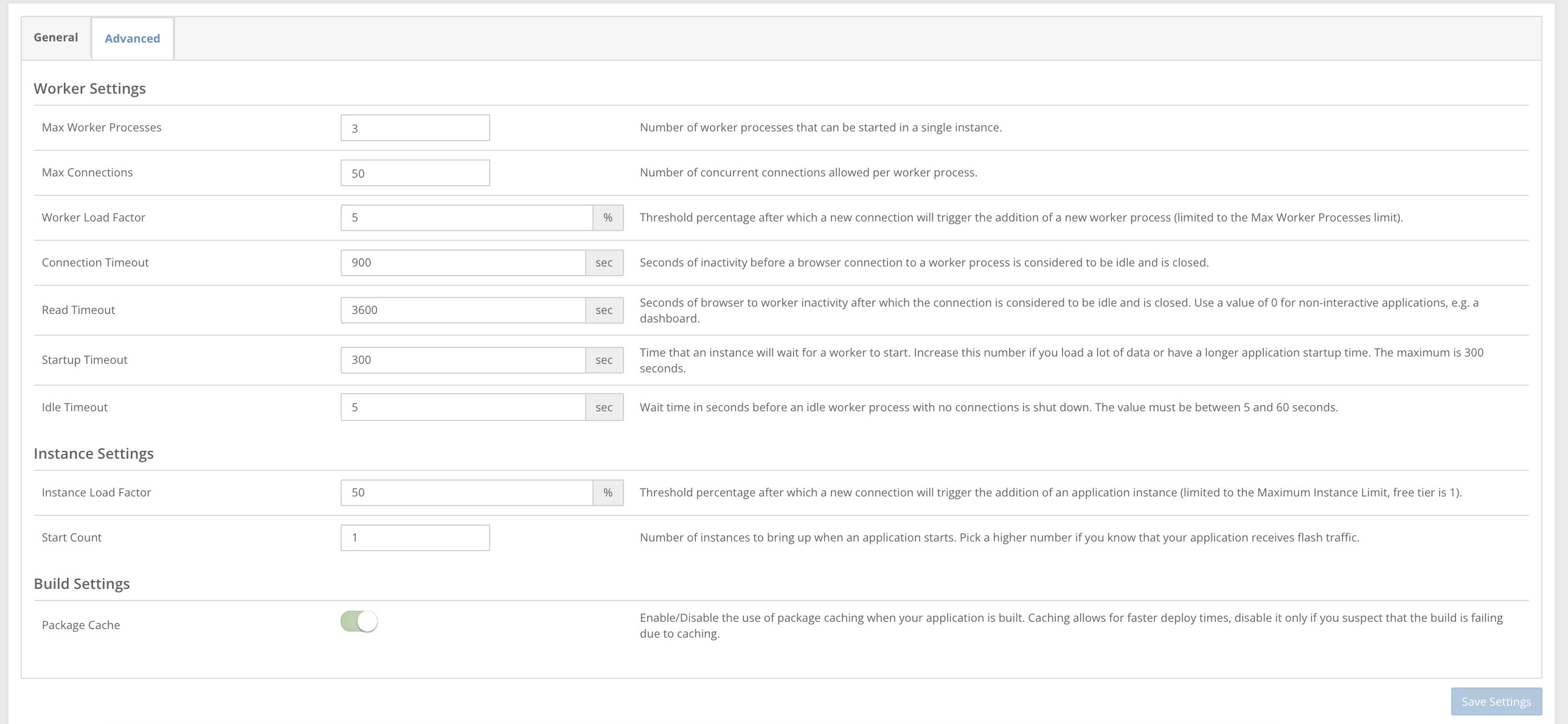
The most obvious culprit is the size of the data files it's working with. It involves two data files, both of which are roughly 15M rows (that would be the objects C4 and C3). That said, these two files equal about 1 GB of data and I'm paying for the Basic Plan, which advertises up to 8 GB of RAM.
Is there anything in my script that might stand out as an immediate red flag (besides the data size) that is causing this?
global.R
library(dbplyr)
library(dplyr)
library(shiny)
library(shinyWidgets)
load("builder_data.RData")
the builder_data.RData file is where the two data files are stored.
ui.R:
library(dbplyr)
library(dplyr)
library(shiny)
library(shinyWidgets)
library(DT)
library(sqldf)
ui <- fluidPage(
titlePanel("Builder"),
sidebarLayout(
sidebarPanel(
radioButtons("mydata", label = "C4 or C3?", choices = c("C4","C3"), inline=TRUE),
selectizeInput("data1", "Select State", selected = "MI", multiple = TRUE, choices = c(unique(sort(C4$state)))),
selectizeInput("data2", "Select County", choices = NULL),
selectizeInput("data3", "Select City", selected = "DETROIT", choices = NULL, multiple = TRUE),
selectizeInput("data4", "Select Demo", choices = c("All", unique(sort(C4$demo)))),
selectizeInput("data5", "Select Registration Status", choices = c("All", unique(sort(C4$registration_status)))),
selectizeInput("data6", "Valid Address", choices = c("All", unique(sort(C4$vb_voterbase_mailable_flag)))),
sliderInput("age", label = h3("Select Age Range"), 18,
35, value = c(18, 20), round = TRUE, step = 1),
sliderInput("turnout", label = h3("Select Turnout Range"), min = 0,
max = 100, value = c(20,80)),
conditionalPanel(condition = "input.mydata=='C4'",
sliderInput("partisan", label = h3("Select Partisan Range"), min = 0, max = 100, value = c(20,80))
),
prettyCheckboxGroup("phones", h3("Only Include Valid Phone Numbers?"), selected = "Yes", choices = list("Yes")),
),
mainPanel(
verbatimTextOutput("universecount"),
tags$head(tags$style("#universecount{color: red;
font-size: 32px;
font-style: italic;
}"
)
)
)
)
)
And finally, server.R:
server <- function(input, output, session){
mydf <- reactive({get(input$mydata)})
observeEvent(input$data1, {
df <- mydf()
updateSelectizeInput(session, "data2", "Select County", server = TRUE, choices = c("All", unique(sort(C4$county[C4$state %in% input$data1]))))
}, priority = 2)
observeEvent(c(input$data1, input$data2), {
req(mydf())
df <- mydf()
if (input$data2 != "All") {
updateSelectizeInput(session, "data3", "Select City", server = TRUE, choices = c("All", unique(sort(C4$city[C4$county %in% input$data2]))))
} else {
updateSelectizeInput(session, "data3", "Select City", server = TRUE, choices = c("All", unique(sort(C4$city[C4$state %in% input$data1]))))
}
}, priority = 1)
filtered_data <- reactive({
req(input$data1,input$data2,input$data3,input$data4,input$data5,input$data6,input$turnout,input$age[1])
temp_data <- mydf()
if (sum("All" %in% input$data1)<1) {
temp_data <- temp_data[temp_data$state %in% input$data1, ]
}
if (input$data2 != "All") {
temp_data <- temp_data[temp_data$county == input$data2, ]
}
if (sum("All" %in% input$data3)<1) {
temp_data <- temp_data[temp_data$city %in% input$data3, ]
}
if (input$data4 != "All") {
temp_data <- temp_data[temp_data$demo == input$data4, ]
}
if (input$data5 != "All") {
temp_data <- temp_data[temp_data$registration_status == input$data5, ]
}
if (input$data6 != "All") {
temp_data <- temp_data[temp_data$vb_voterbase_mailable_flag == input$data6, ]
}
df2 <- temp_data %>% dplyr::filter(age >= input$age[1] &
age <= input$age[2] &
turnout_score >= input$turnout[1] &
turnout_score <= input$turnout[2])
if (input$mydata=="C4") df2 <- df2 %>% dplyr::filter(partisan_score >= input$partisan[1] & partisan_score <= input$partisan[2])
df3 <- if (is.null(input$phones)) df2 else df2 %>% dplyr::filter(!is.na(phone))
df3
})
output$universecount <- renderPrint({
universecount <- paste("Universe Size:", nrow(filtered_data()))
universecount
})
}
If it helps, here is a sample of data that can be used. This can be used for any data object you might encounter (C4, C3, etc...) it doesn't matter. You would just need to extrapolate it to be 15M rows:
structure(list(unique_id = c(36363789L, 18988964L, 16094523L,
39677134L, 4078215L, 28493633L, 3783112L, 18484012L, 13989489L,
14328803L, 14309304L, 9348817L, 33081795L, 32954689L, 30115329L,
17177505L, 34680537L, 13908098L, 5946723L, 6684694L, 28609274L,
1843719L, 20634959L, 5471321L, 26713947L, 17588681L, 30571179L,
17325937L, 29977204L, 9818333L, 17183018L, 9779557L, 6048733L,
18017770L, 21816931L, 5974829L, 16954800L, 38106102L, 5335207L,
8832897L, 32329461L, 15254291L, 14297262L, 39515748L, 31867131L,
31508617L, 31820666L, 33267058L, 20008072L, 13527430L), state = c("TX",
"NC", "MI", "TX", "NV", "TX", "AZ", "MI", "MI", "NC", "MI", "AZ",
"TX", "TX", "TX", "NC", "TX", "MI", "NV", "MI", "TX", "TX", "PA",
"MI", "TX", "NC", "TX", "MI", "TX", "WI", "MI", "AZ", "MI", "NC",
"PA", "MI", "MI", "TX", "NV", "AZ", "TX", "MI", "MI", "TX", "TX",
"TX", "TX", "TX", "PA", "PA"), city = c("BROWNSVILLE", "BURNSVILLE",
"PORT AUSTIN", "NEW BRAUNFELS", "NORTH LAS VEGAS", "SAN ANTONIO",
"ARIZONA CITY", "ROCKFORD", "WARREN", "CHARLOTTE", "PINCKNEY",
"PHOENIX", "BUDA", "FORT WORTH", "LOCKHART", "MATTHEWS", "SAN ANTONIO",
"LIVONIA", "LAS VEGAS", "JENISON", "GOLIAD", "CADDO MILLS", "MEADVILLE",
"BANCROFT", "LITTLE ELM", "ASHEVILLE", "SAN MARCOS", "HAZEL PARK",
"HOUSTON", "CHIPPEWA FALLS", "SOUTH LYON", "QUEEN CREEK", "WYOMING",
"GREENSBORO", "FELTON", "CHARLEVOIX", "WATERFORD", "HUMBLE",
"RENO", "SAN TAN VALLEY", "HOUSTON", "NEW BUFFALO", "PAW PAW",
"HOUSTON", "ARLINGTON", "AUSTIN", "ARLINGTON", "SCHERTZ", "LANCASTER",
"SHIPPENSBURG"), county = c("CAMERON", "YANCEY", "HURON", "COMAL",
"CLARK", "BEXAR", "PINAL", "KENT", "MACOMB", "MECKLENBURG", "LIVINGSTON",
"MARICOPA", "HAYS", "TARRANT", "CALDWELL", "UNION", "BEXAR",
"WAYNE", "CLARK", "OTTAWA", "GOLIAD", "HUNT", "CRAWFORD", "SHIAWASSEE",
"DENTON", "BUNCOMBE", "CALDWELL", "OAKLAND", "HARRIS", "CHIPPEWA",
"OAKLAND", "MARICOPA", "KENT", "GUILFORD", "YORK", "CHARLEVOIX",
"OAKLAND", "HARRIS", "WASHOE", "PINAL", "HARRIS", "BERRIEN",
"VAN BUREN", "HARRIS", "TARRANT", "TRAVIS", "TARRANT", "GUADALUPE",
"LANCASTER", "CUMBERLAND"), age = c(34L, 23L, 21L, 19L, 26L,
26L, 30L, 18L, 26L, 25L, 24L, 22L, 22L, 22L, 30L, 34L, 30L, 28L,
29L, 35L, 27L, 33L, 35L, 35L, 27L, 20L, 24L, 34L, 35L, 26L, 20L,
24L, 31L, 23L, 21L, 31L, 31L, 20L, 33L, 25L, 32L, 27L, 24L, 19L,
31L, 31L, 33L, 35L, 23L, 35L), demo = c("Hispanic", "Caucasian",
"Caucasian", "Caucasian", "Caucasian", "African-American", "Caucasian",
"Caucasian", "Caucasian", "Caucasian", "Caucasian", "Hispanic",
"Caucasian", "Caucasian", "Caucasian", "Caucasian", "Hispanic",
"Uncoded", "Caucasian", "Caucasian", "Caucasian", "Caucasian",
"Caucasian", "Caucasian", "Caucasian", "Caucasian", "Caucasian",
"Caucasian", "Caucasian", "Caucasian", "Caucasian", "Caucasian",
"Uncoded", "African-American", "Caucasian", "Caucasian", "Caucasian",
"African-American", "Caucasian", "Caucasian", "Caucasian", "Caucasian",
"Uncoded", "Caucasian", "Caucasian", "Hispanic", "African-American",
"Caucasian", "Caucasian", "Caucasian"), turnout_score = c(5.9,
54.1, 3.6, 18.4, 1.5, 6.5, 28.3, 21.4, 88.7, 35.4, 20.4, 70.8,
65, 5.8, 17.5, 4.4, 23.1, 81.8, 45.5, 63.3, 3.8, 32.4, 31.4,
89.4, 8.8, 9.1, 3.2, 12.6, 48.5, 24.7, 68.1, 2.9, 23.6, 50, 10.5,
72.3, 83.8, 16.9, 29.5, 20.2, 4.6, 46.9, 65.9, 14.1, 8, 2.5,
20.5, 39, 22.6, 52.6), partisan_score = c(44.4, 1.4, 23.3, 32.7,
91.6, 80, 21.3, 6.9, 66.9, 2.3, 62.5, 99, 12.2, 68, 73.2, 2.2,
92.9, 68.4, 84.6, 10.8, 34.1, 14.7, 0.7, 2, 16.4, 5.5, 87.8,
71.8, 99.7, 18.7, 75.4, 6.9, 84.7, 98.5, 12.3, 1.9, 62.9, 69.9,
1.5, 6.9, 34.5, 42.4, 30.2, 34, 54.6, 88.9, 44.7, 71.5, 98.6,
0.6), first_name = c("firstname1", "firstname2", "firstname3",
"firstname4", "firstname5", "firstname6", "firstname7", "firstname8",
"firstname9", "firstname10", "firstname11", "firstname12", "firstname13",
"firstname14", "firstname15", "firstname16", "firstname17", "firstname18",
"firstname19", "firstname20", "firstname21", "firstname22", "firstname23",
"firstname24", "firstname25", "firstname26", "firstname27", "firstname28",
"firstname29", "firstname30", "firstname31", "firstname32", "firstname33",
"firstname34", "firstname35", "firstname36", "firstname37", "firstname38",
"firstname39", "firstname40", "firstname41", "firstname42", "firstname43",
"firstname44", "firstname45", "firstname46", "firstname47", "firstname48",
"firstname49", "firstname50"), last_name = c("lastname1", "lastname2",
"lastname3", "lastname4", "lastname5", "lastname6", "lastname7",
"lastname8", "lastname9", "lastname10", "lastname11", "lastname12",
"lastname13", "lastname14", "lastname15", "lastname16", "lastname17",
"lastname18", "lastname19", "lastname20", "lastname21", "lastname22",
"lastname23", "lastname24", "lastname25", "lastname26", "lastname27",
"lastname28", "lastname29", "lastname30", "lastname31", "lastname32",
"lastname33", "lastname34", "lastname35", "lastname36", "lastname37",
"lastname38", "lastname39", "lastname40", "lastname41", "lastname42",
"lastname43", "lastname44", "lastname45", "lastname46", "lastname47",
"lastname48", "lastname49", "lastname50"), phone = 1234567890:1234567939,
registration_status = c("Registered", "Registered", "Registered",
"Registered", "Registered", "Registered", "Registered", "Registered",
"Registered", "Unregistered", "Registered", "Unregistered", "Registered",
"Registered", "Registered", "Registered", "Registered", "Registered",
"Registered", "Registered", "Registered", "Registered", "Registered",
"Registered", "Registered", "Registered", "Registered", "Registered",
"Registered", "Registered", "Registered", "Registered", "Registered",
"Registered", "Registered", "Registered", "Registered", "Registered",
"Registered", "Registered", "Registered", "Registered", "Registered",
"Registered", "Registered", "Registered", "Registered", "Registered",
"Registered", "Registered"), vb_tsmart_full_address = c("1 Fake St",
"2 Fake St", "3 Fake St", "4 Fake St", "5 Fake St", "6 Fake St",
"7 Fake St", "8 Fake St", "9 Fake St", "10 Fake St", "11 Fake St",
"12 Fake St", "13 Fake St", "14 Fake St", "15 Fake St", "16 Fake St",
"17 Fake St", "18 Fake St", "19 Fake St", "20 Fake St", "21 Fake St",
"22 Fake St", "23 Fake St", "24 Fake St", "25 Fake St", "26 Fake St",
"27 Fake St", "28 Fake St", "29 Fake St", "30 Fake St", "31 Fake St",
"32 Fake St", "33 Fake St", "34 Fake St", "35 Fake St", "36 Fake St",
"37 Fake St", "38 Fake St", "39 Fake St", "40 Fake St", "41 Fake St",
"42 Fake St", "43 Fake St", "44 Fake St", "45 Fake St", "46 Fake St",
"47 Fake St", "48 Fake St", "49 Fake St", "50 Fake St"),
vb_voterbase_mailable_flag = c("Yes", "Yes", "Yes", "Yes",
"Yes", "Yes", "No", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes",
"Yes", "Yes", "Yes", "Yes", "No", "Yes", "Yes", "No", "Yes",
"Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes",
"Yes", "Yes", "Yes", "Yes", "No", "Yes", "No", "Yes", "Yes",
"Yes", "Yes", "Yes", "Yes", "Yes", "No", "Yes", "Yes", "Yes",
"Yes")), class = "data.frame", row.names = c(NA, -50L))