I have moved my Shiny APP code to an app.R document, and added a global.R file to load my files only once to save memory per this suggestion (https://stackoverflow.com/questions/67316766/word-prediction-app-using-too-much-shiny-memory?noredirect=1#comment118987824_67316766) The app loads and functions correctly locally and it does deploy to shiny.io without memory issues.
{kind=link}
But, I am now receiving the following error regarding the object 'combined sample':
Error in value[3L] : object 'combined_sample' not found Calls: local ... tryCatch -> tryCatchList -> tryCatchOne -> Execution halted
I tried inserting the 'corpus_train' function into the app.R file just above the shiny. (Data object not found when deploying shiny app)
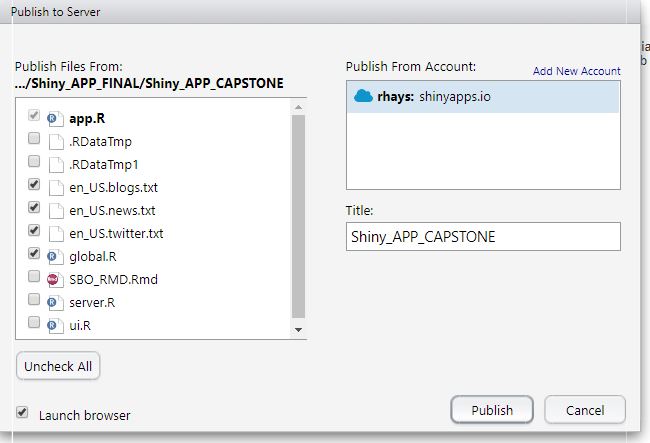
The attached image is a screen grab of the files that I uploaded to shiny.io for the deployment.
How do I get shiny to find this object after deployment to the shiny servers?
MUCH appreciation in advance for the help of the Community!
**global.R**
library(sbo)
library(shiny)
library(processx)
blog <- readLines("en_US.blogs.txt", warn=FALSE, encoding="UTF-8")
twit <- readLines("en_US.twitter.txt", warn=FALSE, encoding="UTF-8")
news <- readLines("en_US.news.txt", warn=FALSE, encoding="UTF-8")
twit_sample <- sample(twit, length(twit)*.05)
news_sample <- sample(news, length(news)*.05)
blog_sample <- sample(blog, length(blog)*.05)
combined_sample <- c(twit_sample, blog_sample, news_sample)
combined_sample <- iconv(combined_sample, "UTF-8","ASCII", sub="")
corpus_train <- sbo_predictor(object = combined_sample,
N = 3,
dict = target ~ 0.75,
.preprocess = sbo::preprocess, # Preprocessing transformation
EOS = ".?!:;",
lambda = 0.4,
L = 3L, # Number of predictions for input
filtered = "<UNK>"
)
**app.R**
library(sbo)
library(shiny)
shinyUI(pageWithSidebar(
headerPanel("Predicitve Text APP"),
sidebarPanel(
textInput("text", label = h3("Text input"), value = "Enter text..."),
),
mainPanel(
h4("Predicted Words:"),
verbatimTextOutput("result_output"),
h6("This APP generates three predicted next words based on the text you input.
The prediction algorithm relies on word frequencies in the English twitter,
blogs, and news datasets at:"),
h6(a("http://www.corpora.heliohost.org/")),
br(),
h6("Created April 2021 as part of my Captsone project for the
Data Science Specialization provided by Johns Hopkins University and Coursera.
All code can be located on GitHub at:") ,
h6(a("https://github.com/themonk99/predictive.git"))
)
))
corpus_train <- sbo_predictor(object = combined_sample,
N = 3,
dict = target ~ 0.75,
.preprocess = sbo::preprocess,
EOS = ".?!:;",
lambda = 0.4,
L = 3L,
filtered = "<UNK>"
)
shinyserver <- function(input, output) {
output$result_output <-renderText({
predict(corpus_train,input$text)
})
}
# Run the application
shinyApp(ui = ui, server = server)