My question is about the problem of setting working directories for blog posts based on projects where some analysis has been done elsewhere.
I have a GitHub repo here that replicates everything.
The basic problem is outlined and to a certain extent solved here. So the insight about submodules is golden. I regularly have local GitHub repos where I do a ton of recoding, data cleaning and prep and analysis and then I want to move over and write a punchy blog post about something. So Tim's solution is perfect.
I have a hugo website directory with a set up like content/post/external_data/submodule (as per Tim's advice) and I clone the main project repo into submodule.
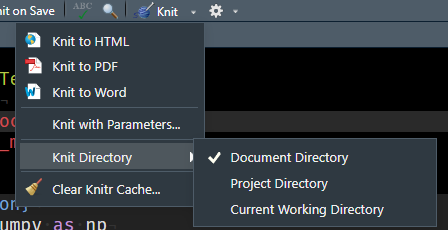
Following Tim's advice, in the Rmd file, I set the working directory with root.dir to be External_Data/Submodule and then call an R script to import data in External_Data/Submodule/R_Scripts/1_data_import.R
When I knit the RMarkdown file, using Tim's set up, everything works perfectly (Clone the repo, open Blog_Post/Test.Rmd and knit to see, or see the attached screenshot).
That Rmd file imports a csv file in data subfolder, stores it as dat and then glimpses it. So far so good....
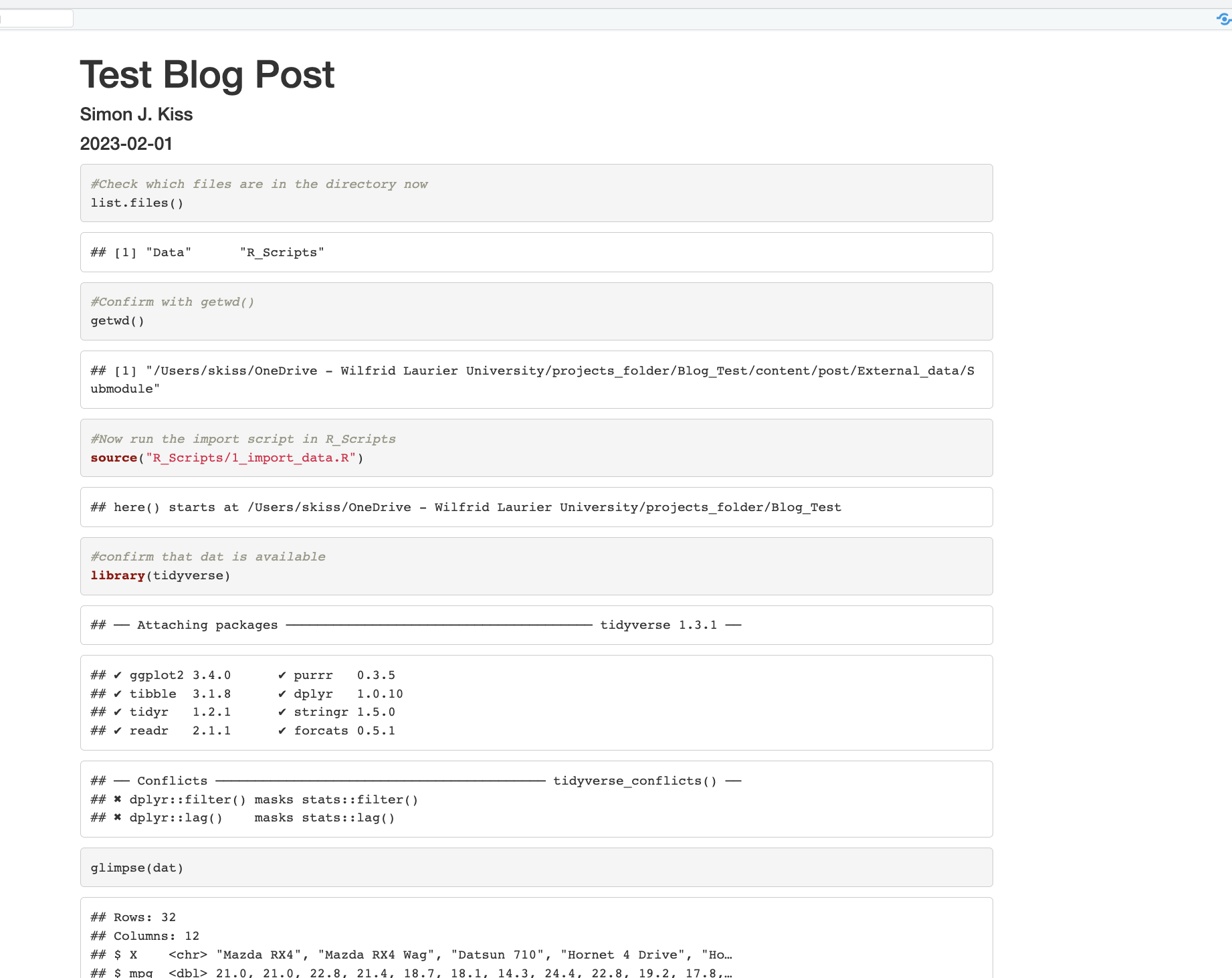
But the problem is, to make this really work, I need to be able to execute that pre-existing data import scripts in the RMarkdown document chunk by chunk so that I can then fool around with the data and make the graphs and analyses I want for the blog post.
But I cannot get find a way to execute the chunks in the RMarkdown file one -by-one .
I hope I have explained myself here, if someone were to take a moment and clone the repo and knit the document and then try to execute the chunk sourcing the data import script, you should see what I mean.
Thanks for any help.