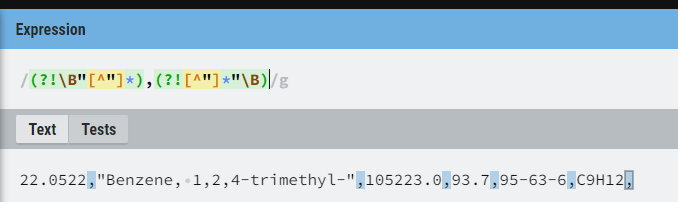
Hi, I have a CSV file that I need to import into RStudio. The columns are comma separated, but there are names that include the comma: Benzene, 1,3-dimethyl- and I don't need to separate them, however the function separates them:
separate(df, sep =",")
How can I separate the columns according to the comma, but keep the name that contains the comma, without separating it?
This is an extract from de csv file:
Component RT,Compound Name,Component Area,Match Factor,CAS#,Formula,Estimated Conc.
18.6510,"Benzene, 1,3-dimethyl-",1370644.1,98.5,108-38-3,C8H10,