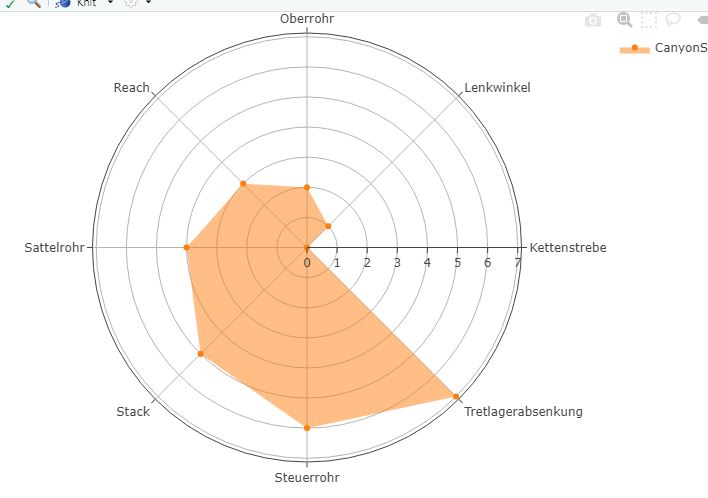
I'm trying to build a scatterplot and have problems with assigning the correct r value. Here you have a glimpse at my dataset:

As you see, the first column represents the names of bikes, columns 2 to 11 show different geometry data. I want the scatterpolar to look like this:
plot_ly(
type = 'scatterpolar',
mode = 'markers',
fill = "toself",
r = c(435, 65.5, 629, 1193, 434, 440, 73.5, 635, 100, 32),
theta = c("Kettenstrebe", "Lenkwinkel","Oberrohr","Radstand","Reach","Sattelrohr","Sitzwinkel","Stack","Steuerrohr",
"Tretlagerabsenkung"),
showlegend = TRUE,
name = ComparisonTable[1,1])
How can I define the r value in a way, that it automatically shows the values of the desired row, without me putting in every and each value?
I tried the following code, but without success:
plot_ly(
type = 'scatterpolar',
mode = 'markers',
fill = "toself",
r = as.matrix(ComparisonTable[1]),
theta = c("Kettenstrebe", "Lenkwinkel","Oberrohr","Radstand","Reach","Sattelrohr","Sitzwinkel","Stack","Steuerrohr",
"Tretlagerabsenkung"),
showlegend = TRUE,
name = ComparisonTable[1,1])
I am happy to get your expertise on the problem!