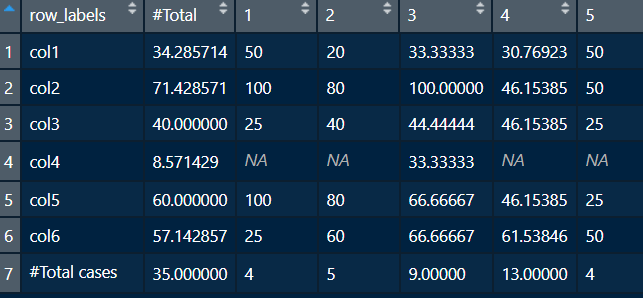
I have a dataframe as pic below,
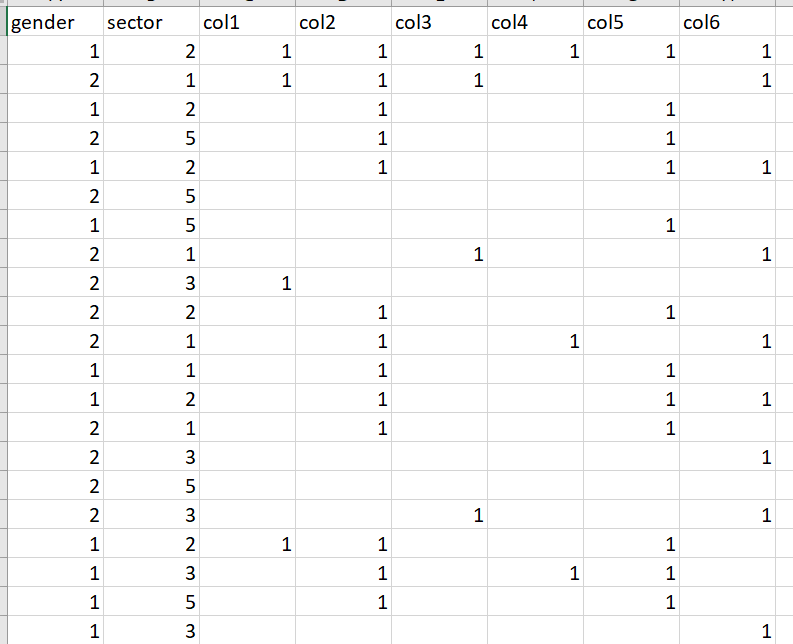
gender sector col1 col2 col3 col4 col5 col6
1 2 1 1 1 1 1 1
2 1 1 1 1 1
1 2 1 1
2 5 1 1
1 2 1 1 1
2 5
1 5 1
2 1 1 1
2 3 1
2 2 1 1
2 1 1 1 1
1 1 1 1
1 2 1 1 1
2 1 1 1
2 3 1
2 5
2 3 1 1
1 2 1 1 1
1 3 1 1 1
1 5 1 1
1 3 1
1 1 1 1 1 1
2 4 1 1 1 1
1 1 1 1 1 1 1
2 4 1 1 1 1
1 1 1 1 1
2 2 1
2 1
2 1 1 1
1 1 1 1
2 4 1 1
1 5 1 1 1 1
2 4 1 1 1
1 5 1 1 1 1
2 4 1 1 1 1
1 1 1 1 1 1
2 4 1
2 1
2 2 1 1 1
i am trying to create a function like below for SPSS like tables
df <- data
var_list <- c("col1","col2","col3","col4","col5","col6")
grouping_var <- "sector"
df1<-df[var_list] %>% as.data.frame()
grouping_var <- rlang::parse_expr(grouping_var)
var_lab(df[[grouping_var]]) <-""
var_lab(df1[1]) <- ""
var_lab(colnames(df1)[ncol(df1)]) <- ""
data1 <- df %>% select(all_of(grouping_var)) %>% cbind(df1)
tab1 <- data1 %>%
tab_cells(mdset(col1 %to% col6)) %>% tab_cols(total(), data1[1]) %>%
tab_stat_cpct() %>% tab_pivot()
every thing is working manually.
actually i am trying to give my first value var (col1) and last value var(col6) dynamically, so that function can automatically select first value variable and last value variable to calculate, first column of "data1" will always be grouping variable.