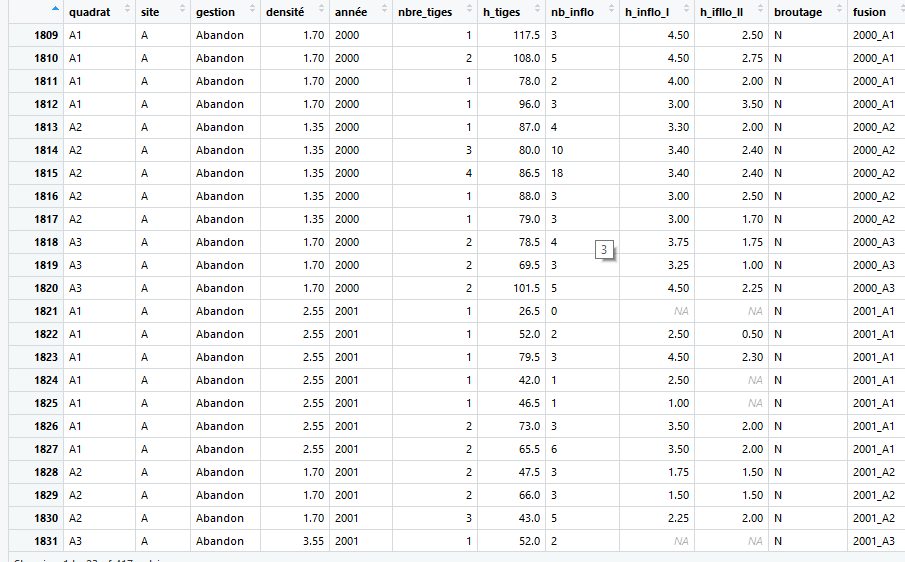
I created a column "fusion" that combine "quadrat" and "année" and I would like to select only unique value of "fusion" in order to have corresponding values in "densité".
There is the function unique() but it list the unique values of "fusion" and don't select the entire row in order to do a new data table with "densité"'s values.
I would like to have the same table but without the duplicates so :
quadrat site gestion densité année ... fusion
A1 A Abandon 1.70 2000 2000_A1
A2 A Abandon 1.35 2000 2000_A2
A3 A Abandon 1.70 2000 2000_A3
I hope I've been clear
Thanks for your help,
Cordially
Some of the columns between annee and fusion are not unique. Do you want to drop them like this.
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
df <- data.frame(A = rep(c(1:3), each= 4),
B = rep(c("A", "B", "C"), each = 4),
C = c(1:12),
D = rep(c(2000:2002), each = 4))
df
#> A B C D
#> 1 1 A 1 2000
#> 2 1 A 2 2000
#> 3 1 A 3 2000
#> 4 1 A 4 2000
#> 5 2 B 5 2001
#> 6 2 B 6 2001
#> 7 2 B 7 2001
#> 8 2 B 8 2001
#> 9 3 C 9 2002
#> 10 3 C 10 2002
#> 11 3 C 11 2002
#> 12 3 C 12 2002
df %>% select(-C) %>% unique()
#> A B D
#> 1 1 A 2000
#> 5 2 B 2001
#> 9 3 C 2002
Created on 2019-05-17 by the reprex package (v0.2.1)
If not, what values from them do you want to keep?
"Some of the columns between annee and fusion are not unique"
Yes, but it doesn't matter bc for what I want to do I don't need these columns.
I want to delete duplicates of the columns "fusion" in order to have the values of "densities" per quadrat and per year
Let's call your data frame df.
For your request to make sense, densities has to be constant for a given combination of quadrat and year. You could do any of the following.