Using seewave, I have sequential 1 minute audio files which I need to loop through to determine the signal:noise ratio. The ratio is correct for the first few files, then starts producing the wrong value for all subsequent files. I know this because when I run the files individually the correct ratio is produced.
E.g.
test<-readMP3("Audio/4_28NOV19_0442_C1 246.mp3")
# create an amplitude over time plot, with a threshold in which anything above the amplitude threshold is signal and anything below is noise
chirptest<-timer(test, f=44100, threshold=80, envt="hil", msmooth=c(100,0),
colval = "blue", plot=TRUE, xlab = "nochirp")
chirptest$r
= 1.5E-04
However, the output df from the loop says that the ratio of "Audio/4_28NOV19_0442_C1 246.mp3" is 3.7E-05.
Strangely, the incorrect values are repetitive, e.g.:
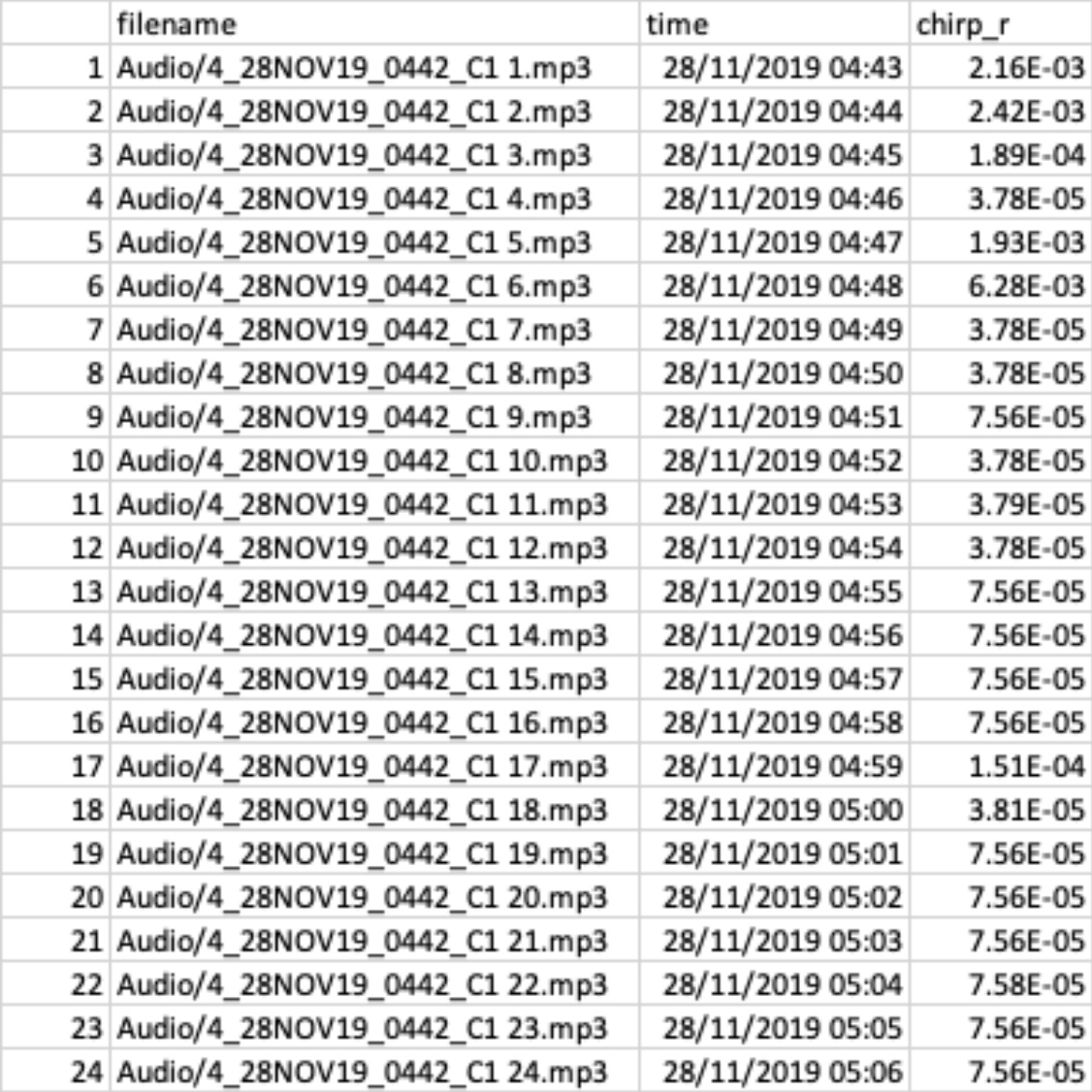
Here's my code, essentially I've written a loop that:
- imports the file and creates a blank df
- uses the seewave
Timer function to create an amplitude threshold - pull the ratio ($r) of signal:noise from Timer and populate that in a new df
- create a new df with relevant info & saves as csv
#import audio files and sort in correct order
files <- list.files("Audio", pattern="*.mp3", full.names=TRUE)
files <- mixedsort(files)
#create an empty dataframe to populate with data
df <- data.frame(chirp_r = NULL,filename=NULL)
#Create list of chirp values
for (i in files){ #Look inside your list of files (see above, called 'files')
print(i) #take each file one by one, show on screen what it's working on
data_inside_loop <- readMP3(i) #run readmp3 on each file one by one
chirp <- timer(data_inside_loop, f=44100, threshold=80, envt="hil", msmooth=c(100,0), colval = "blue", plot=FALSE)
df <- rbind(df, data.frame(chirp_r=chirp$r, filename=i))} #populate df with the new data, one line at a time
df$filename <- as.character(df$filename) #turn the file name into characters
df$filename_without_mp3 <- substr(df$filename, 1, nchar(df$filename)-4) #remove last 4 characters from the name (i.e. remove ".mp3)
#this code gives you each of the numbers in the character string
str_extract_all(df$filename_without_mp3,"\\d+\\)?") #see the starting time is always the 4th number in the filename
#str_extract_all finds all the numbers and puts them in a list
#the sapply part takes out the 4th number from that list
#that fourth number is the starting time
df$starting_time <- sapply(str_extract_all(df$filename_without_mp3,"\\d+\\)?"), "[[", 4)
#convert it to time so R understands what it is
df$starting_time <- format(as.POSIXct(strptime(df$starting_time,"%H%M",tz="")), format = "%H:%M")
#use filename to construct a full correct date and time
df$t <- paste0(sapply(str_extract_all(df$filename_without_mp3,"\\d+\\)?"), "[[", 2), #2nd number from filename is day
"/11/", #November
sapply(str_extract_all(df$filename_without_mp3,"\\d+\\)?"), "[[", 3), #3rd number from filename is year
" ", #add a space
df$starting_time) #add time
#convert time string into a format R understands as time
df$t <- as.POSIXct(df$t, format="%d/%m/%y %H:%M", tz="GMT") #yay now R understands our date and time
#the last number from the filename is the minutes elapsed
df$elapsed_min <- sapply(str_extract_all(df$filename_without_mp3,"\\d+\\)?"), "[[", 6)
#sapply always saves stuff as characters so need to tell r that elapsed_min is a number
df$elapsed_min <- as.numeric(df$elapsed_min)
#add the elapsed time column (as minutes) to the starting time
df$time <- df$t + minutes(df$elapsed_min)
#new df
df <- df %>% dplyr::select("filename","time","chirp_r")
#write csv
write.csv(df_padded,file = paste0("Output/df_padded.csv"))
Can anyone please advise why this is happening and how I correct for it? If of interest, the goal here is that I run this code through sequential audio files of crickets chirping, to determine time-of-day of calling. I've broken down my weeklong audio files into sequential 1 minute files for workability in R.
*Update, I've just re-ran the loop on my massive list of audio files and it's now only produced the correct ratio for the first file, then file 2 is incorrect, it then repeats the same incorrect ratio for a lot of subsequent files and continues being incorrect.