Hi to everyone, I'm new at this community and a beginner with R.
I have the following script, with this, I update my POS database with POS diary sales.
Blockquote
library(rJava)
library(xlsx)
library(xlsxjars)
a <- read.xlsx("1.xls", 1)
b <- read.xlsx("2.xls", 1)
c <- read.xlsx("3.xls", 1)
d <- read.xlsx("4.xls", 1)
e <- read.xlsx("5.xls", 1)
f <- read.xlsx("6.xls", 1)
TOTAL <- rbind(a, b, c, d, e, f)
Base_de_datos_a_actualizar <- read.xlsx("base de datos.xlsx", 1)
Base_de_datos_a_actualizar$NA..2 <- NULL
Base_actualizada <- rbind(Base_de_datos_a_actualizar, TOTAL)
Base_actualizada <- Base_actualizada[!duplicated(Base_actualizada),]
write.xlsx(Base_actualizada, "base de datos.xlsx")
Blockquote
This script works fine, but I want to how could I read a list of files without writing the name of each one, combine them and write a xlsx file.
Consider something along this piece of code; it is built on the excellent {fs} package, which has a function to list all files matching a condition - in this case MS Excel files.
To this list is then applied a function reading the filename & appending it to the global result. Note the use of <<- operator, as the function reaches "outside" to the global data frame.
The code assumes constant structure of all the excels (otherwise the rbind would break).
library(fs)
library(readxl)
result <- data.frame() # global init
excel_normalize <- function(filename) { # function to read the excel & append it to result
asdf <- readxl::read_xlsx(filename)
result <<- rbind(result, asdf)
TRUE
}
list_of_excels <- dir_info("./xls/",recursive = T, glob = "*.xlsx") # find all excels
sapply(list_of_excels$path, excel_normalize) # apply the function
Here's a pattern I often use to read and combine multiple files with a similar structure:
library(tidyverse)
library(readxl)
f <- list.files(pattern="xls$")
TOTAL <- map_df(f, read_excel)
A base R version would be:
TOTAL <- do.call(rbind, lapply(f, function(file) read_excel(file)))
Note that rbind will throw an error if the files don't all have the same column names. On the other hand map_df will combine all of the files, regardless of the column names. For example, run the following and see what happens:
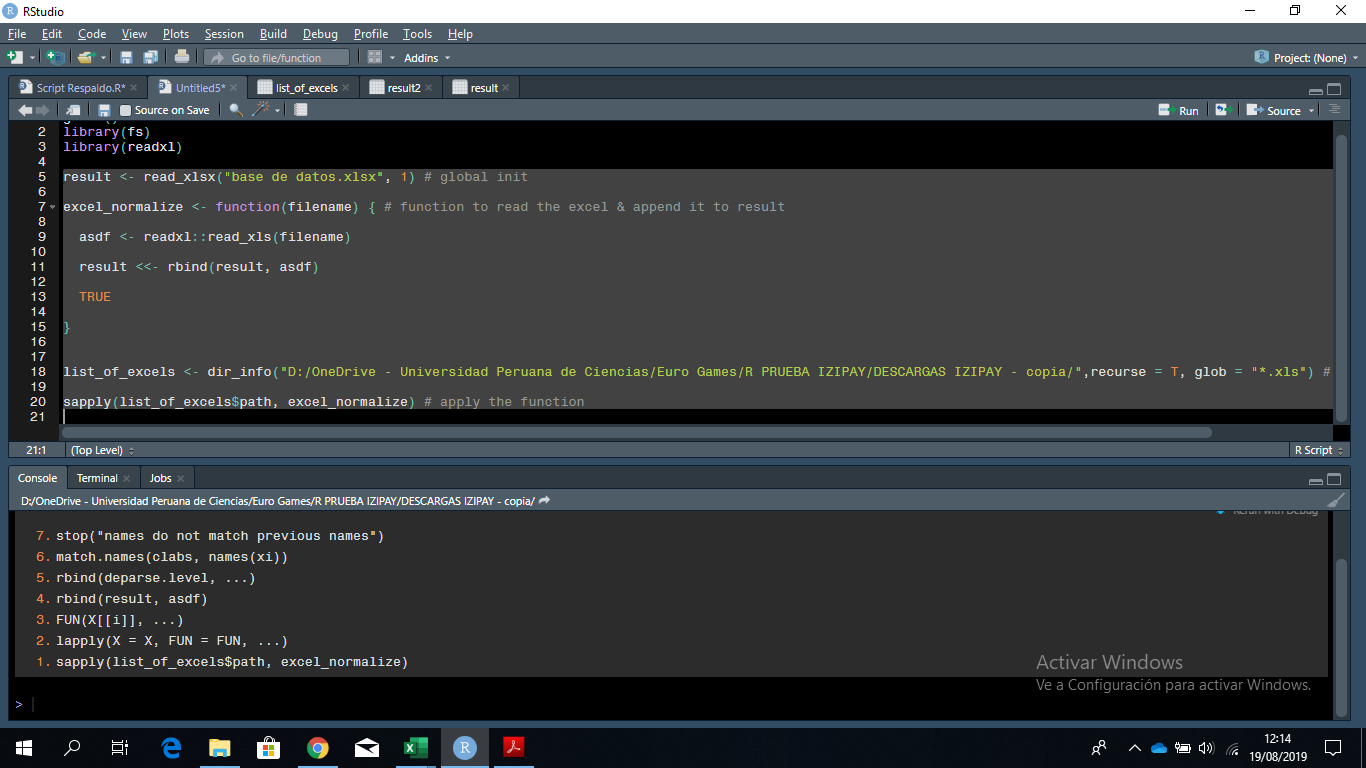
sapply(list_of_excels$path, excel_normalize) # apply the function
I get the following error
Error in match.names(clabs, names(xi)) :
names do not match previous names
7.stop("names do not match previous names")
6.match.names(clabs, names(xi))
5.rbind(deparse.level, ...)
4.rbind(result, asdf)
3.FUN(X[[i]], ...)
2.lapply(X = X, FUN = FUN, ...)
1.sapply(list_of_excels$path, excel_normalize)
All steps before was OK. I just modified .xlsx to xls.
Objects have same column number
And do all of the excels have the same structure? It seems that in your case they do not...
If you are absolutely positively sure that the structure is the same you could either force them, or pick only some; you could also force a vector of field names onto all your imports. Either by:
# base R approach
names(asdf) <- c("whatever", "names", "you", "are", "certain", "of") # place this in between `read_xls` and `rbind` calls
or
# tidyverse approach
asdf <- readxl::read_xlsx(filename) %>%
select(only those columns you are interested in)
either way it pays to double check your structures and source of files. The constant structure is a very important assumption in my proposed approach.