I'm not sure why you are getting that error but even the example in the R Documentation for readHtmlTable() gets the same error as you do. Also note that the XML package is marked as orphaned on CRAN ( https://CRAN.R-project.org/package=XML ) and was last updated since June 2017. It's probably not a good idea to use this package on new stuff if you can avoid it.
Below is the first readHTMLTable example in the example code included with the XML package. Note that it produces the same error that you get.
library(XML)
temp2 <- "https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population"
tables <- readHTMLTable(temp2)
#> Error: XML content does not seem to be XML: 'https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population'
As is your code needs to be hand edited for us to try it out because of how quotes are treated when they are pasted.
Also try to prune down the example as much as possible... this one does not need rJava or xlsx packages.
I can duplicate the 21 records you get. But you need to show us what you expect to get, i.e. why is 21 the wrong number?
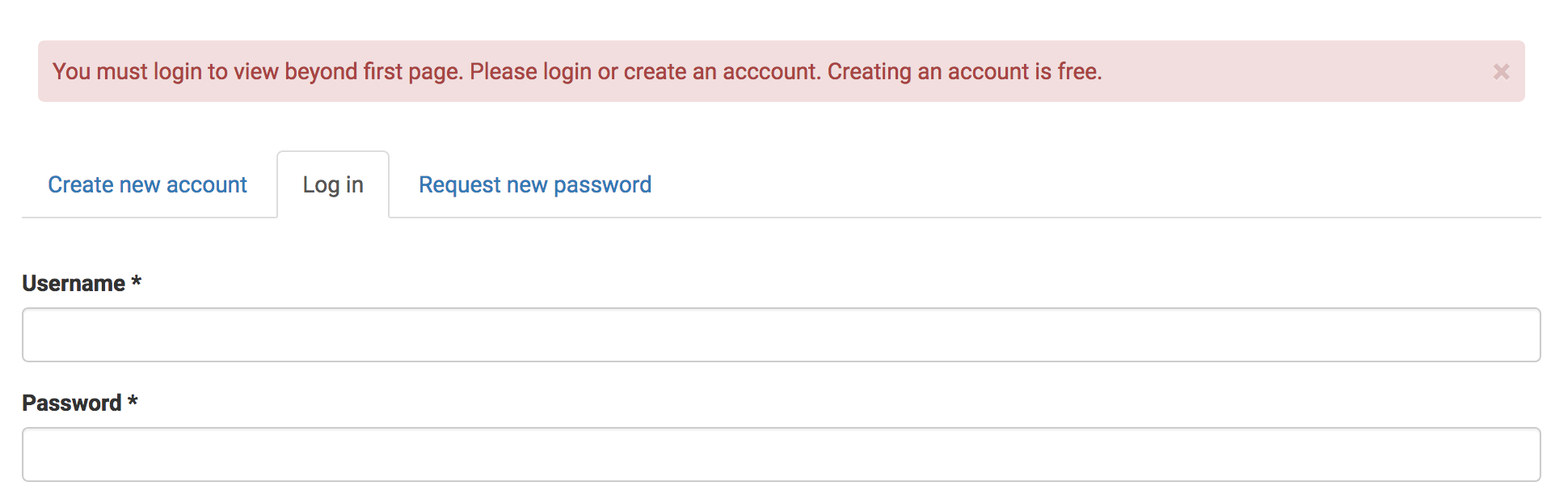
Have you tried manually accessing the pages to see their content? I appears that page two and beyond requires security credentials to access it which is my guess as to why you are only seeing 21 samples in the output... the other three pages are just warning pages that you can't access without logging in first.
A reprex makes it much easier for us to help you. All the help you get here is from people using their spare time to help you so it is much appreciated when you minimize the work needed to answer your questions. A reprex is the best way to do that.
It looks like you may need to figure out login credentials and ensuring that your connection from R has permission to view the pages that you are accessing. This can be done a myriad of ways. I hate to point you down the path of RSelenium, but that is an option. There is probably a way to set a header / cookie to use your login credentials manually in your program, as well, since this is static content. I would look into the xml2 package a bit for related functions, as well.
Since there are only 4 pages, you could obviously download the HTML files yourself and then access them locally. That doesn't help if you want this process to be automated / reproducible, though.
In general, I encourage you to keep your URL labels with the data it came from, as it would have made it clear that you were having problems on successive pages. The other approach is to try a handful of URLs manually (i.e. fetchData(1), fetchData(4)), and see what you get before firing off the ol' ldply.
EDIT: I basically just said the same thing as @danr. Oops
Thank you very much. You are right the site has some login credentials required for accessing more than one page. I will have to figure out through some searches how i can do this. I am a novice and a starter in this area.
Reprex is not working on my machine and i see that it has now been orphaned as of 26 January 2018. I am using a MacBook Pro. How can i make reproducible code to post?
There is a temporary glitch in CRAN which is causing your problem. You need to install reprex directly from github for now. You can do that from the console window in R Studio:
devtools::install_github("tidyverse/reprex")
or you can just make an R script with that line in it and run it.
Try this instead: devtools::install_github("tidyverse/reprex")
It is probably because quotes changed to a different ASCII code from what they supposed to be.