Hi, I am wondering how would it be possible to scrap images from a website in bulk and save them on my computer. I already tried the following code and it successully saves the URL links but only downloads the first element/image from the vector or data frame when i try to use the download.file() function:
for (i in 1:5) { #change 100 with your number of rows to read through
myurl <- paste(imagedf[i,1], sep = "") #you need the exact column number so change 1 to that value and change df to your dataframe's name #same as above
download.file(myurl,"imagedf$links.jpg", mode="wb")
}
The issue here is that your output file is always the same so even in your for loop you are downloading the files but save them all into imagedf$links.jpg.
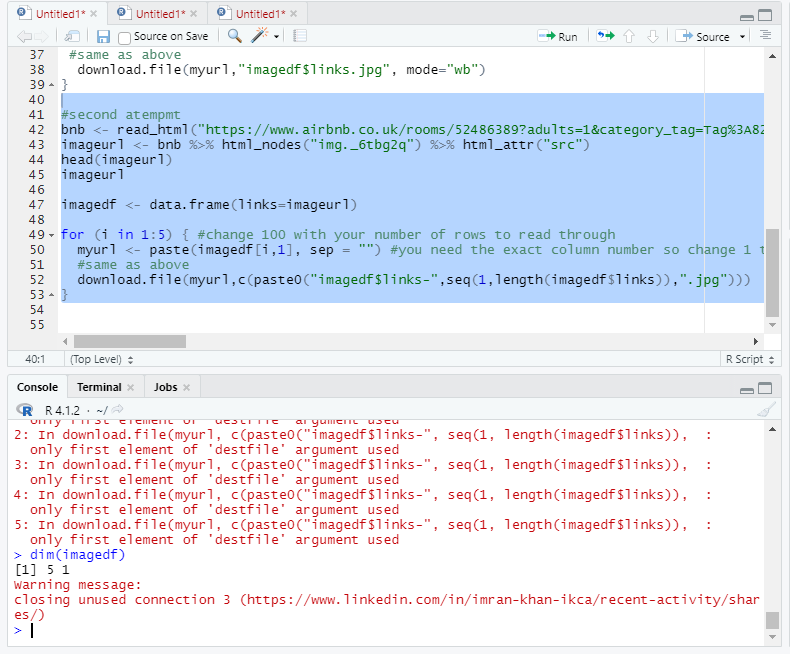
Hi thank you so much for the reply. That make sense, but when I try to follow your suggested code and try to save them in different files, it gives me an error that only the first argument of destfile is used in the download.file function. Moreover, it is also giving me the saved files as corrupted now for some reason.
I am attaching the error message here, any help would be really appreciated.
It seems like I may have misexpressed myself. The code I shared with you previously was meant to replace the for loop altogether and have only a single download.file() call as the IMHO better option when compared to a for loop. But the for loop is still possible. Find below both options properly commented in an example code based on yours.
library(textreadr)
library(rvest)
bnb <- read_html("https://www.airbnb.co.uk/rooms/52486389?adults=1&category_tag=Tag%3A8225&children=0&infants=0&search_mode=flex_destinations_search&check_in=2022-05-20&check_out=2022-05-27&federated_search_id=1f863c44-cdf7-4e16-ab2d-3b1b7d5aed91&source_impression_id=p3_1648663537_0jW9B28n%2B98bVjKI")
imageurl <- bnb %>% html_nodes("img._6tbg2q") %>% html_attr("src")
head(imageurl)
imageurl
imagedf <- data.frame(links=imageurl)
# Option 1 - Use one single download.file() call to download all images
download.file(imagedf$links, c(paste0("/tmp/imagedf$links-",seq(1,length(imagedf$links)),".jpg")))
# Option 2 - Use a for loop and download one image after the other.
for (i in 1:5) { #change 100 with your number of rows to read through
myurl <- paste(imagedf[i,1], sep = "") #you need the exact column number so change 1 to that value and change df to your dataframe's name
#same as above
download.file(myurl,paste0("/tmp/imagedf$links-",i,".jpg"), mode="wb")
}