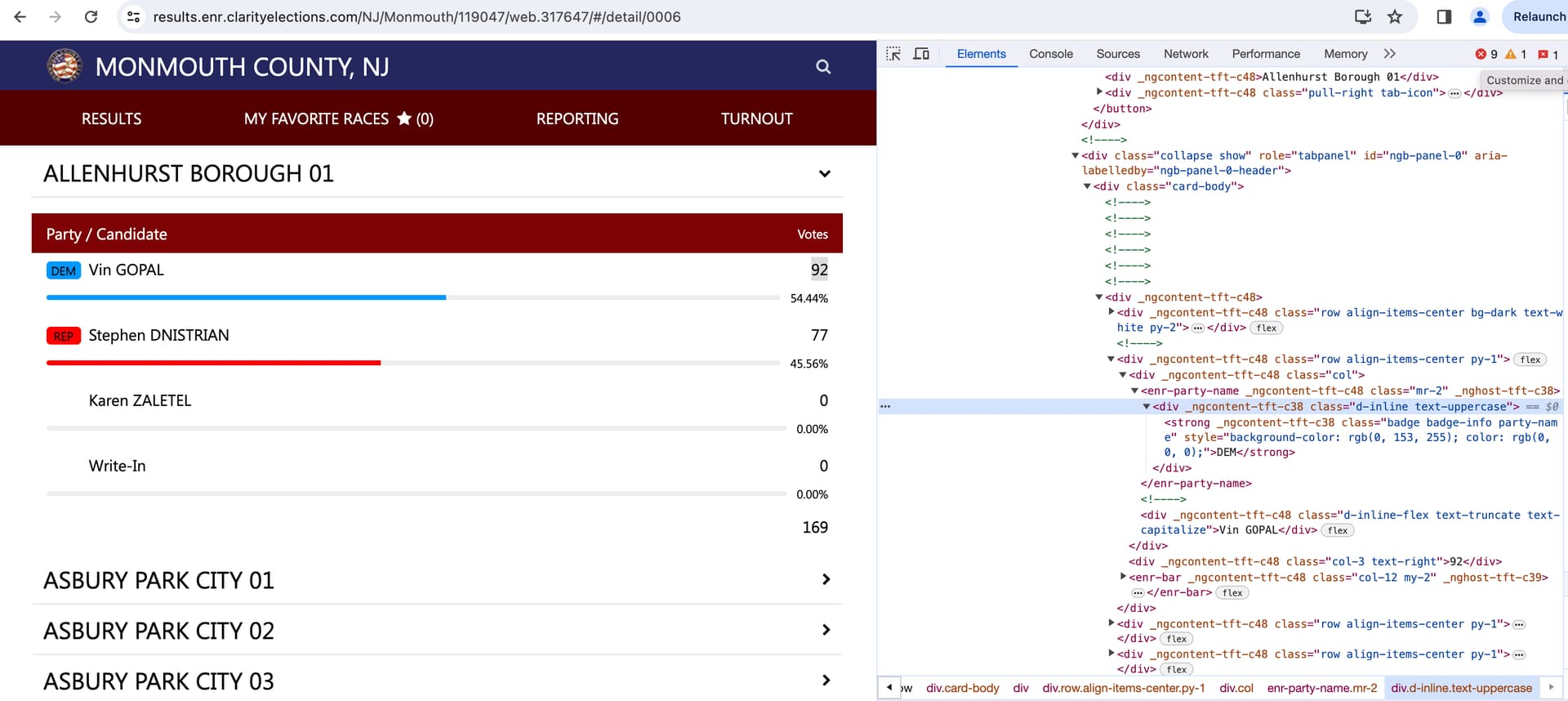
Hi, so, I would like to scrape precinct election results from this county website. I only care about taking the precinct name, candidate party, candidate name, and raw vote tally for each precinct.
I know this is a live page (even though the election was months ago), so using the standard read_html tools won't really do me much good. I know rvest recently added an experimental read_html_live feature to the package that runs chromote in the background, but I can't say I have a great grasp on how to make it work.
Attached is a picture of the part of the webpage I am looking at and some of the associated html code. You can see within the code some of the elements I am looking to extract (I.E.: <div _ngcontent-tft-c48="" class="col-3 text-right">92</div> and <div _ngcontent-tft-c48="" class="d-inline-flex text-truncate text-capitalize">Vin GOPAL</div>)
This is a much more substantial rvest challenge than the simple vignettes that accompany the package, and I cannot tell if I am simply not capable of scraping the page, or if it's actually not feasible. So, truly, if anyone can help lead me in the right direction of working with live web pages, picking the correct selectors, and accessing the text I want and getting it into R, that would be tremendously appreciated.
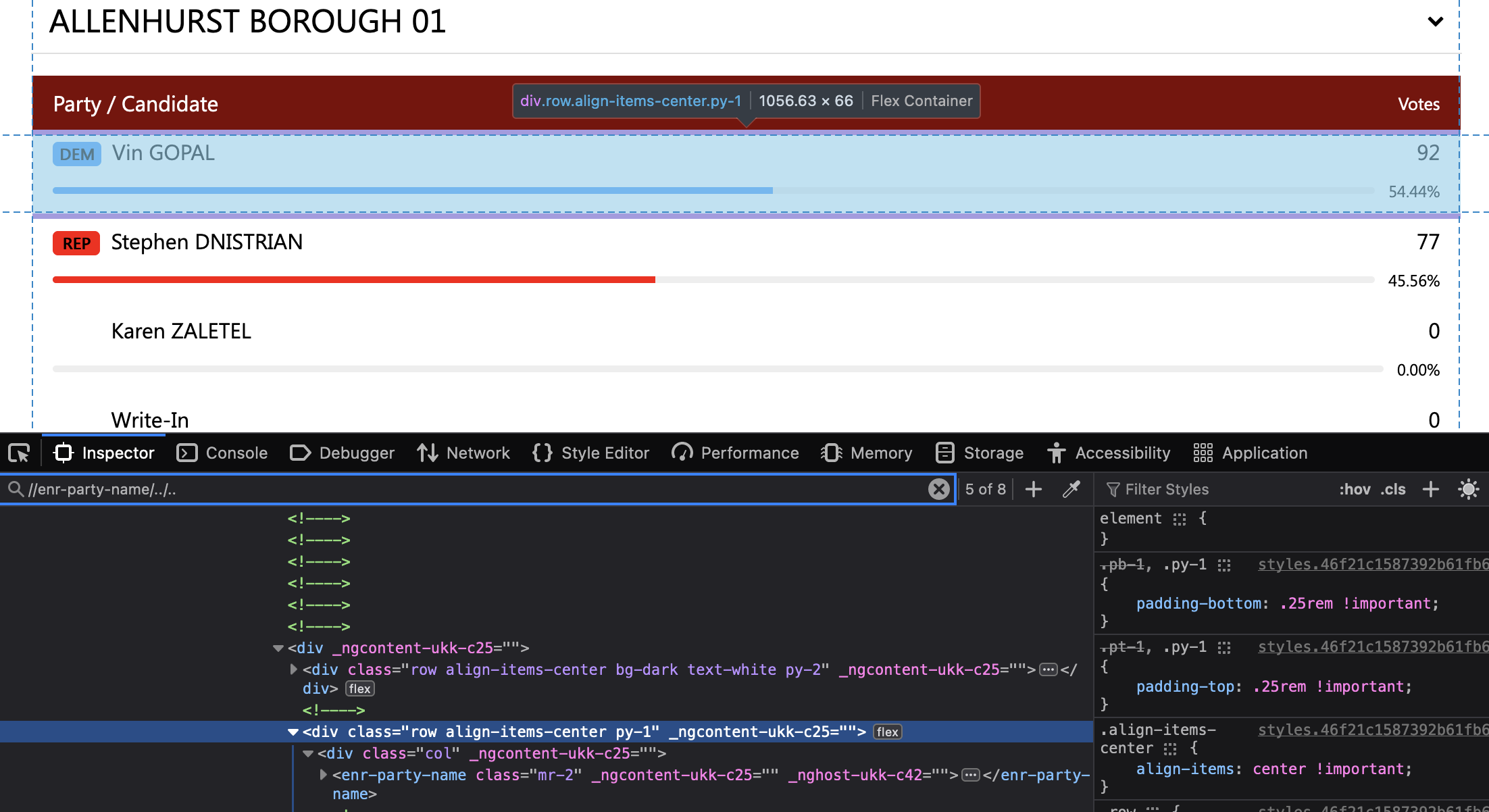
Looking at the screenshot, looks like you might want the parent elements as the selector. For example: end-party-name over the child did that actually contains the text. Dunno if the screen shot shows the full picture though
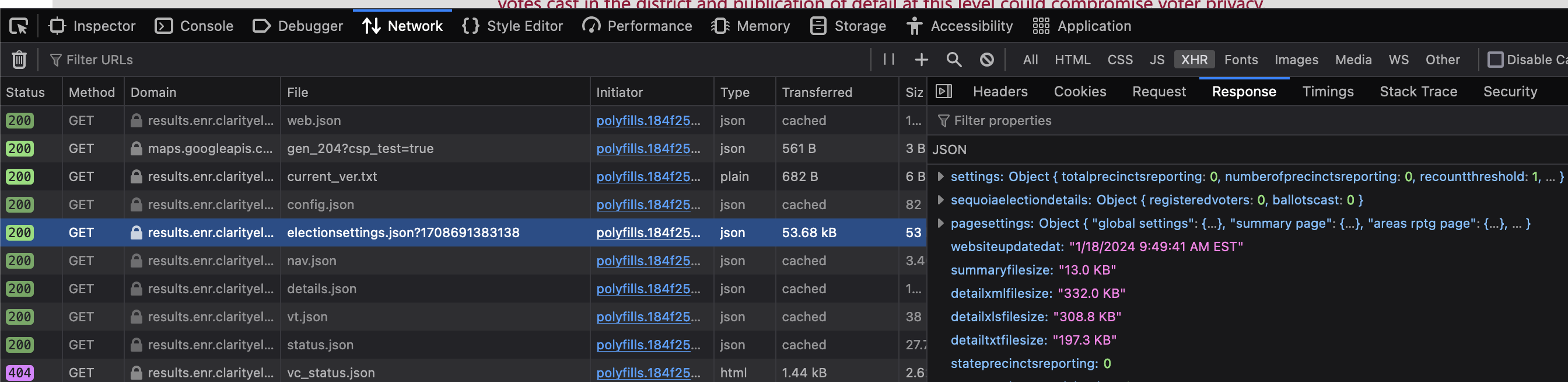
Ok, getting the underlying JSON is SOOO much easier ! This is a humungous help, thank you!
My longterm goal is to make a little election results database of the county for myself; I don't know if there is an automated way to get to the JSON for each Election Day of each year, but this shortens the amount of time I have to put in tremendously.
My super longer-term goal is to somehow scrape this data live on election night and then create my own version of a NYT needle for local races, but we must crawl before we can run a marathon!
If you want to go the data route, then I would just follow along with the Network tab in the web dev tools. Filter by XHR and looks like the page makes a call every 30 seconds or so to update the page if there are any updates:
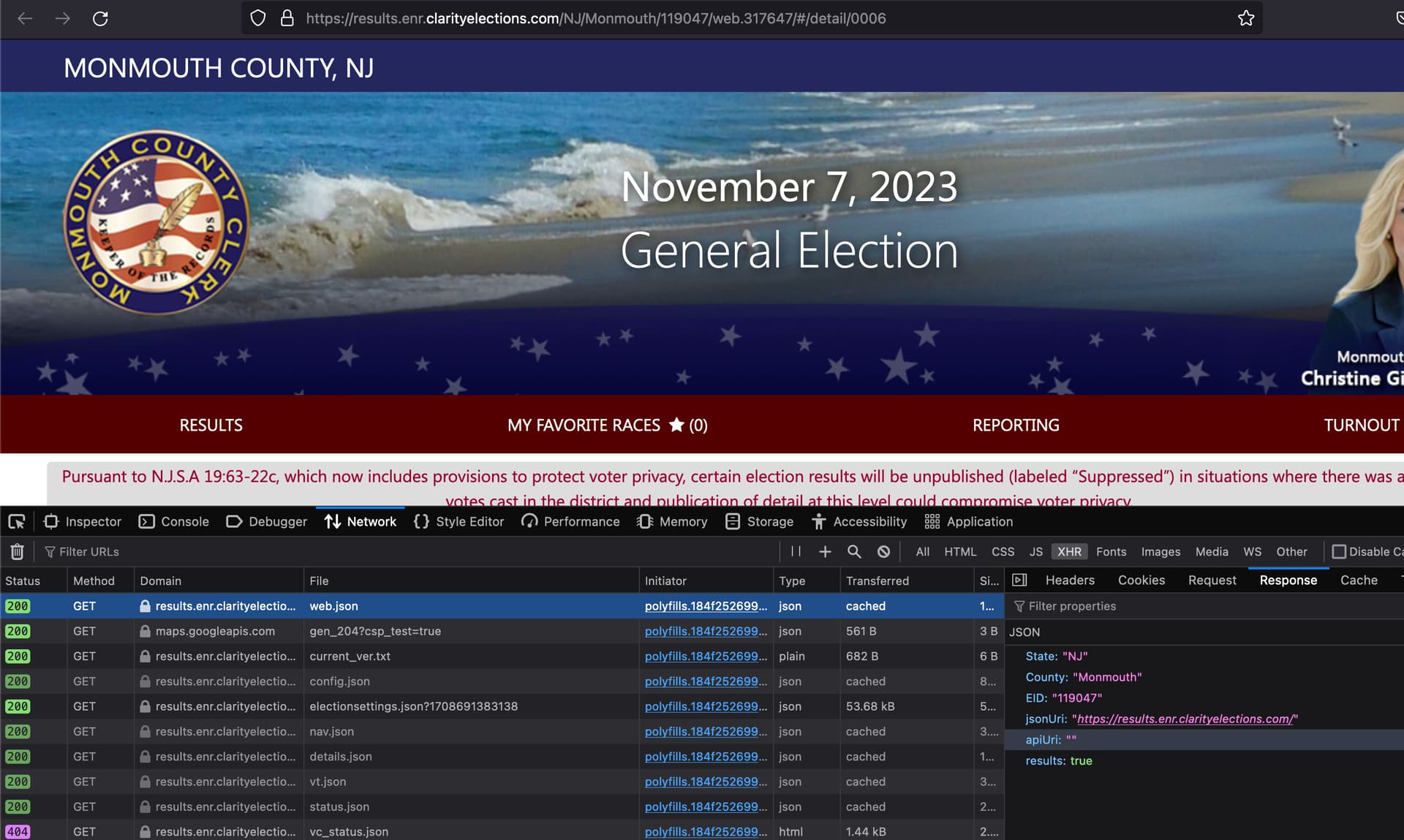
Also, looks like there is a EID (Election ID I would guess) that is also in the URL. So that might be the clue as to how to get multiple elections after you get one parsed