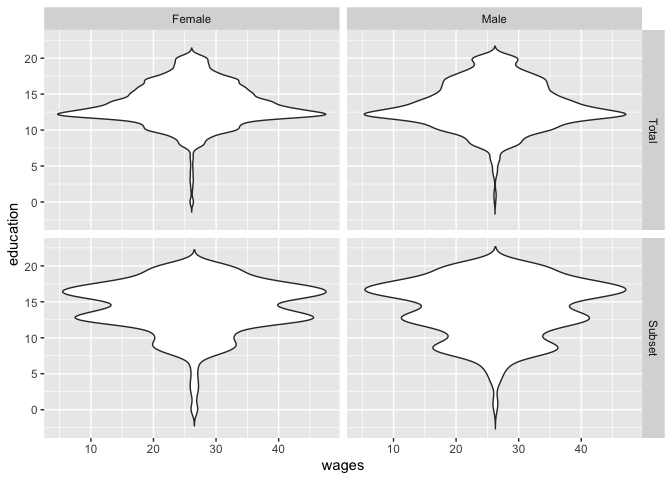
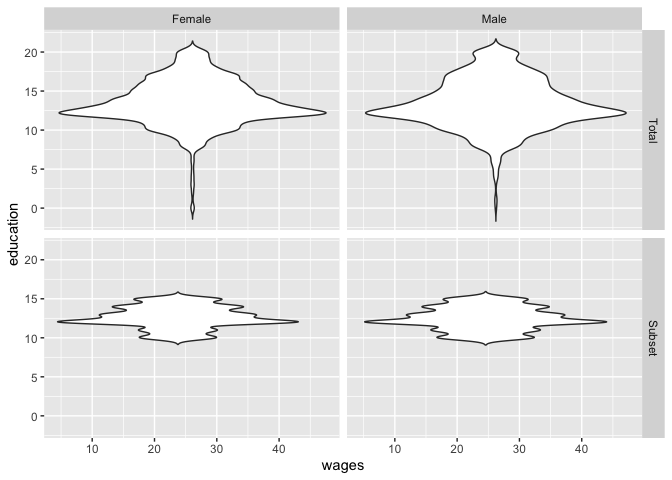
The problem is, that the Violin Plots are not scaled the same. In the bottom picture it appears there are as many observations for education = 16.5 as there are for education = 12 in the upper plot. I want both of these Plots' width to be scaled the same (by the maximum observations of a token), so I can compare them better. For example a token with 100 observations in the upper plot should have the same width as a token with 100 observations in the bottom plot.
I have tried to do that using the scale options for geom_violin and aes, but unfortunately that didn't work because it just scales on the given data. You can't give an argument for a relative width to an exact value. Does anyone have an idea how to scale the plots properly?!
Whenever possible, I try to make {ggplot2} handle the scaling for me. The best way to do that is generally to have ALL of the data you intend to plot in the same data frame and then pass it to ggplot to process.
Using your example above, here is how I might go about it:
Thanks for your answer.
This is undoubtedly a better looking code, unfortunately it doesn't solve my problem either. Again, the lower plots are not adjusted to the width of the upper plot. I haven't figured out yet why the scaling is not completely the same, but also here, for example, at education = 16.5, different scales are given for the frequency.
In the end, the lower plots shape should remain the same, and only be compressed in width.
I'm sorry, I find it really hard to explain the problem in a precise and understandable way. I will try again with an example:
Looking at the data table of the data SLID2$group == "Total" and SLID2$group == "Subset", there are the same number of observations (308) for 'education = 16'. Now I want to clarify this in the plot below by making the width of the violin plots at the point 'education = 16' the same (because of the same number of observations). Right now, comparing the two plots, it looks like there are many more observations with 'education = 16' in the lower dataset than in the upper. So I mean that the width of the lower plot adjusts to the relative scaling of the upper plot.
I know that this comparison would be meaningless in my minimal example, that was just chosen to have an example as simple as possible. In the data set from which the problem originates, this comparison of different violin plots is desired. But because of the different scaling it is difficult to understand intuitively by the reader of the report.
I don't know if something like this is even possible, but that would be what I need. I hope this explains my problem better.
Thanks for being so patient and helping me.
A couple of things, violin plots are smooth densities, which means they present summaries of your data, and not absolute values of your data. So even if two datasets/groups have the same exact number of observations at any particular level (e.g. education==16), we do not necessarily expect that the violin plot is exactly the same width at that point, because the surrounding data changes the local context for density smoothing.
Secondly, it's possible that the code below isn't doing precisely what you think it's doing.
SLID[!SLID$education %in% 10:15, ]
This code is just removing people whose education value is exactly 10, 11, 12, 13, 14, or 15. Is that your intended goal of that code? Without any context it just seems like perhaps that is not the intended effect and may contribute to the differences in plots.
I just realized my problem is not solvable/logical, because of the characteristics of the Violin Plots. Since the Violin plots are made with the kernel density estimation, which area sums up to one, it's not possible to have the same scaling for different observation numbers. I'll go on and just do it with bar plots and print the observation numbers per plot on topleft.
Nevertheless, your code example using 'tidyverse' helped me understand how it works, so that my code will become much more compact. The deletion of the values 10:15 was just for the example, to have a different maximum of observation maximums for the data sets and show the problem.
Thanks for your effort.