I am a bit perplexed - I have .rds files with each containing a large data.frame (4 columns by ~ 2 million rows). I'm doing some quality control, so my process is to read in the file, remove the offending rows, and save as a new .rds file as to not overwrite the raw data.
However the second "quality control" file (thousands of rows smaller), when saved as an .rds, is larger than the original by a decent amount.
I can replicate this with the 'volcano' dataset:
v = volcano
v = reshape2::melt(v)
saveRDS(object = v, file = "test.rds")
t = readRDS("test.rds")
t = t[which(t$value < 180),]
saveRDS(object = t, file = "test2.rds")
The file test.rds is 6 KB and test2.rds is 17 KB on my computer.
str() shows that their data types are the same. I tried other ways of indexing as well but the result is the same.
The only difference in this example is that using the volcano data the filtered data frame is larger than the original:
Whereas in my case the second object.size is smaller, while the output file size is larger.
Hoping this is something silly I overlooked.
Cheers, thanks!
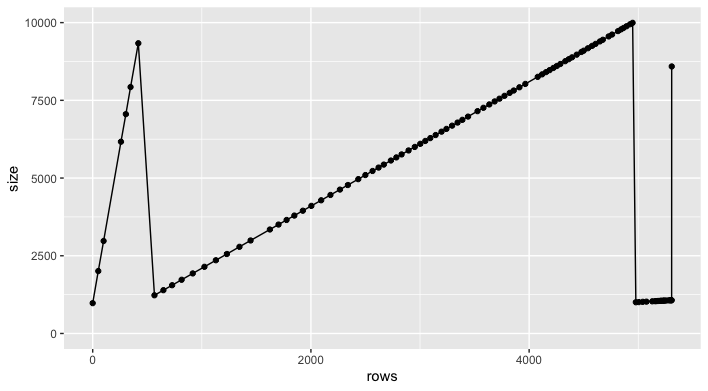
Interesting example. I'm curious too what the explanation is. When I tried different cutoffs for the volcano example data, I saw an interesting non-monotonic relationship between # of rows and object size. I'm guessing this might be something like GIF compression, where the file is small when there are contiguous blocks with the same value, but if you have sharp deltas (as would happen if you exclude some rows, so the sequences are broken up) the file gets bigger, even if there are fewer pixels depicted...
As another piece of evidence for this theory, I note that shuffling the order of the volcano data set (by default an ordered grid) will make the file 40x bigger, now 427k instead of 10k.
library(dplyr) # I'm sure there's a better way to shuffle, this just came to mind first!
object.size(v %>% rowwise() %>% mutate(rand = runif(1)) %>% arrange(rand) %>% select(-rand))
# 427264 bytes
In my case the files are 7 to ~30 MB in size each, then re-saved about 40% larger. E.g. one is 19.9 MB, filtered and saved again 27.6 MB ... it's adding up to a lot of extra space.
Ah and I believe you've found the answer - if I sort before saving (in this case I have lon, lat, value, time, sorting by lon and lat) the file is smaller!