I'm not aware that you could solve this easily with any one liner ; but it seems to be a question of writing code that can order strings based on the order of the final numbers in them, and the presence /absence of symbols representing inequalities, so with some effort you could write a function to do this.
Thanks very much for taking the time out to answer this question.
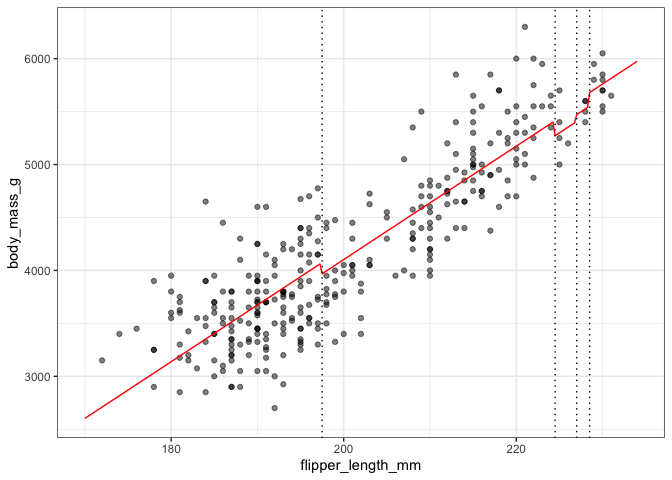
Im not sure I am following. If the algorithm generates a rule below, are not two rules redundant here?
I ask because my use case is that we have to fill out an excel sheet for a tool that basically picks items for inspections. We only have one slot for each attribute so in the case of classifying penguins above we would only be able to have one value for bill_depth_mm, flipper_length_mm and flipper_length_mm
These might be redundant if they were used in a tree-based model but ruleFit adds them to a linear model along with the original predictor. This allows it to model the predictors used in the splits in nonlinear ways.