I'm wondering what the difference is in font display between printed tibble objects and basic results. I have a student trying to do text analysis on Ancient Greek text, that includes diacritics (from this block) on Windows. (AFAICT, Ancient Greek has more diacritics than modern Greek, which is why this is hard.) Although I can get the following block to work perfectly on my Mac, for her it produces a lot of output
involving code points printing to screen.
library(tidyverse)
library(tidytext)
a = read_lines("http://benschmidt.org/thuc.xml") %>% tibble(text = .)
tokens = a %>% unnest_tokens(word, text) %>%
filter(word %>% str_detect("[A-Za-z0-9]", negate = TRUE)) %>% #Hacky way to strip XML tags.
count(word)
tokens %>% arrange(-n) %>% head
I get καὶ to display on the screen as the most common word; she gets κα<U+1F76>, or, if we decompose w stri_trans_nfd, και<U+0342>. (The first is from a newer Unicode block where Greek letters are combined with diacritics--the second seems to indicate that even after decomposing, she doesn't have the diacritic block or at least the ability to compose the standard Greek/Coptic block with it).
All this is sort of ordinary Unicode-is-hard stuff. I get that you can't display every code point on every system. The thing that's weird to me is that although this happens when displaying inside a tibble, when she uses pull to extract into a straightforward character vector, the composite vectors do display, albeit in some weird alternate font where the diacritic letters are sketchier.
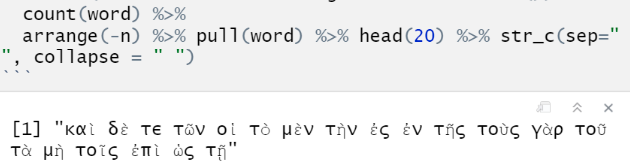
So the question is: is there anyway to set the display font used inside print.tibble (or whatever the function is) so that it mimics this behavior instead of bailing out to printing the code points?
(For the record/future Googlers, we do have a 95% workaround for display, which is just to strip the diacritics like so: remove_diacritics = function(word) stringi::stri_trans_nfd(word) %>% str_replace_all("\\p{M}", ""). And maybe she can learn to read code points. But I'm far enough down the rabbit hole now that I wonder if there's a perfect solution we could use, or else some underlying flaw in Windows Unicode support just inside tibbles.