library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
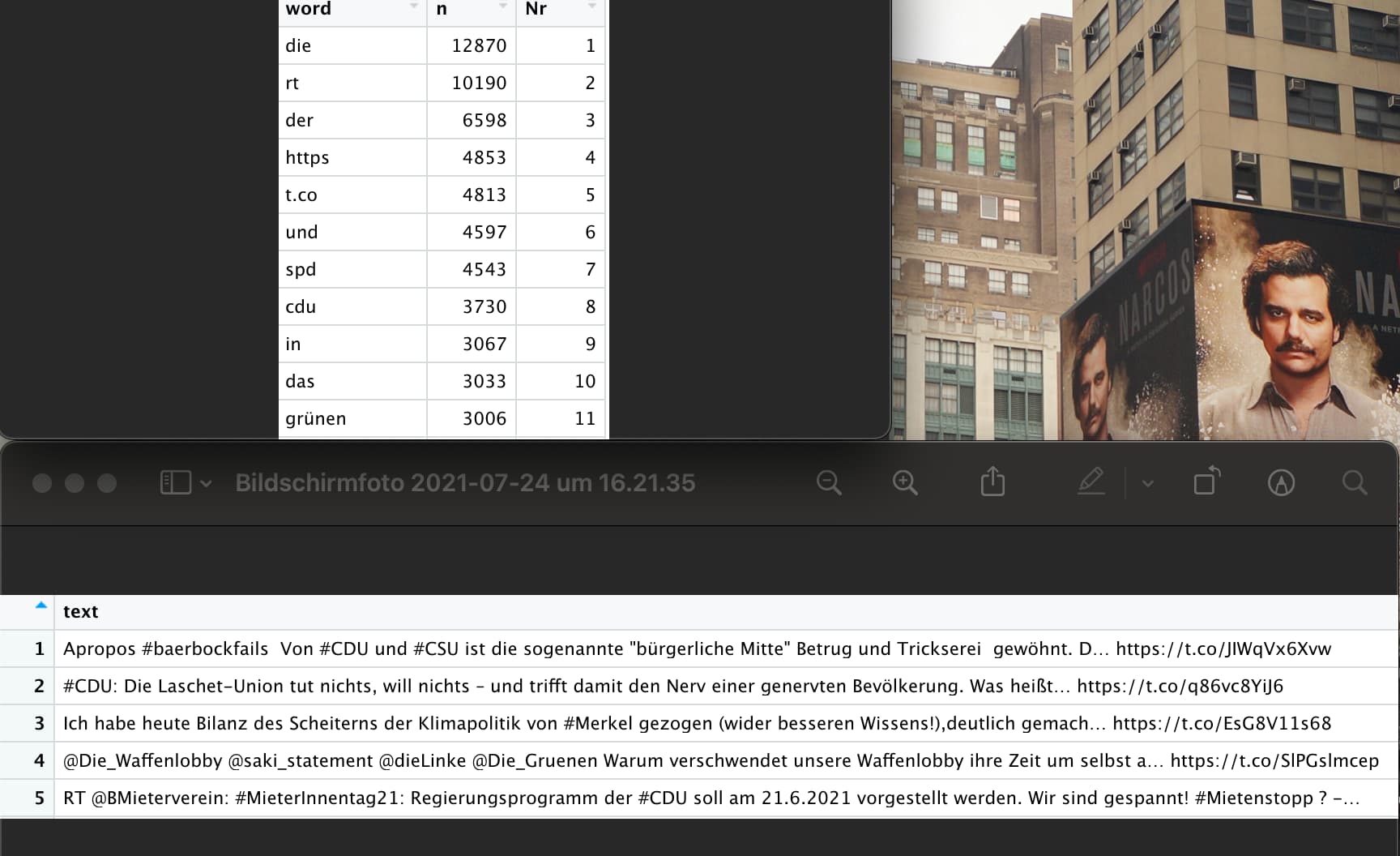
# generate frequency table
freq <- data.frame(
stringsAsFactors = F,
words = c("die","rt","der"),
n = c(12870,10190,6598)
) %>%
arrange(desc(n)) %>%
mutate(nr=row_number())
# generate tweet table from character tweet
tweet <- "Bitte rt der Tweet"
tweettxt <- data.frame(
stringsAsFactors = F,
tweetwords = (strsplit(tweet," ")[[1]])
)
# combine the two tables: column `n` will contain the frequencies, `nr` the ranks
tweetnum <- tweettxt %>%
left_join(freq,by=c('tweetwords'='words')) %>%
mutate (n = ifelse(is.na(n),0,n),
nr = ifelse(is.na(nr),Inf,nr))
tweetnum
#> tweetwords n nr
#> 1 Bitte 0 Inf
#> 2 rt 10190 2
#> 3 der 6598 3
#> 4 Tweet 0 Inf
Created on 2021-07-24 by the reprex package (v2.0.0)
thank for your Help, but unfortunately that is not my solution.
My goal is that every word in the twitter dataset (Text) is replaced by their frequency rank of the whole twitter dataset (15000 tweets).
I already ranked all words by their frequency. The whole dataset has 18420 words, so every word in the text got a rank by their frequency.
Now I want that the words in the tweets are replaced by the frequency rank. So every word is replaced by the rank of the word frequency, between 1 and 18420.
For example the first tweets should look like this:
Original tweet:
Apropos #baerbockfails Von #CDU und #CSU ist die sogenannte "bürgerliche Mitte" Betrug und Trickserei gewöhnt.
The transformed tweet should then look like this:
Words replaced by word frequency rank:
[2890] [2629] [14] [8] [6] [48] [13] [1] [1282] [2460] [972] [1733] [6] [16698] [11959]
I hope I could clarify my point and looking forward for every help!
Hello @Pingi ,
I think I understand your problem.
Because you did not provide a reprex (always much appreciated) I created one where my small freq data.frame takes the place of your 18420 words dataset.
If you want to change the format to the one with [ and ] you can use
# we use OpenRepGrid to generate random words
random_words = OpenRepGrid::randomWords(1000)
# then we get a dictionary with frequency of each word
freq = table(random_words)
# text with some words from random_words
tweet = "what happened to Mr. Johnson"
# text is splitted
tweet_words = strsplit(tweet, "\\s")[[1]]
# we replace word in the text by the frequency
paste0("[", na.omit(freq[tweet_words]),"]", collapse = "") # na.omit is here to remove words that are not in the dictionary
A last step would be to do this for every tweet of the dataset and transfer the values of each tweet in a dataset with the format of the original twitter dataset.
So there is the value for the first tweet in the first row, the second value in the second row for the second tweet and so on...