Thanks for including some of your data and code. To make a reproducible example, all the data and code someone else would need should be included. Therefore, using read_csv() on a file that is only on your computer is not reproducible. A better way is to use tribble() or dput() to include a sample of your data in the code as I do below.
After creating the sample data, I do the string replace as I wrote in my previous code. Does this accomplish what you are trying to do?
library(tidyverse)
raw_armed_conflicts <- tribble(
~data_id, ~event_date, ~year, ~event_type, ~region, ~country, ~iso3, ~latitude, ~longitude, ~fatalities,
"1892808", "20-Oct-18", "2018", "Battle-No change of territory", "Eastern Africa", "Burundi", "BDI", "-2.8772", "29.3253", "4",
"1892831", "20-Oct-18", "2018", "Violence against civilians", "Middle Africa", "Cameroon", "CMR", "5.9333", "10.1667", "3",
"1892860", "20-Oct-18", "2018", "Battle-Government regains territory", "Northern Africa", "Egypt", "EGY", "31.1316", "33.7984", "4",
"1892861", "20-Oct-18", "2018", "Battle-No change of territory", "Northern Africa", "Egypt", "EGY", "31.2163", "34.1107", "0",
"1892874", "20-Oct-18", "2018", "Strategic development", "Eastern Africa", "Ethiopia", "ETH", "12.9667", "36.2", "0",
"1892875", "20-Oct-18", "2018", "Violence against civilians", "Eastern Africa", "Ethiopia", "ETH", "10.15", "36.35", "6",
"1892920", "20-Oct-18", "2018", "Battle-No change of territory", "Western Africa", "Mali", "MLI", "14.795", "-1.318", "1",
"1892921", "20-Oct-18", "2018", "Violence against civilians", "Western Africa", "Mali", "MLI", "16.6314", "-3.3256", "0",
"1892922", "20-Oct-18", "2018", "Riots/Protests", "Western Africa", "Mali", "MLI", "16.8425", "-3.8559", "1",
"1892961", "20-Oct-18", "2018", "Violence against civilians", "Western Africa", "Nigeria", "NGA", "12.1492", "12.9907", "12",
"1892962", "20-Oct-18", "2018", "Violence against civilians", "Western Africa", "Nigeria", "NGA", "11.4953", "12.9688", "2",
"1893075", "20-Oct-18", "2018", "Non-violent transfer of territory", "Eastern Africa", "Somalia", "SOM", "3.0399", "43.7969", "0",
"1893076", "20-Oct-18", "2018", "Riots", "Eastern Africa", "Somalia", "SOM", "8.4064", "48.4819", "0",
"1893282", "20-Oct-18", "2018", "Violence against civilians", "Southern Asia", "Afghanistan", "AFG", "33.6457", "62.2696", "0",
"1893283", "20-Oct-18", "2018", "Violence against civilians", "Southern Asia", "Afghanistan", "AFG", "34.5195", "65.2509", "6",
"1893284", "20-Oct-18", "2018", "Strategic development", "Southern Asia", "Afghanistan", "AFG", "34.9145", "65.2884", "0",
"1893285", "20-Oct-18", "2018", "Violence against civilians", "Southern Asia", "Afghanistan", "AFG", "34.3448", "61.4932", "0",
"1893286", "20-Oct-18", "2018", "Battle-No change of territory", "Southern Asia", "Afghanistan", "AFG", "34.5167", "69.1833", "16"
)
raw_armed_conflicts %>%
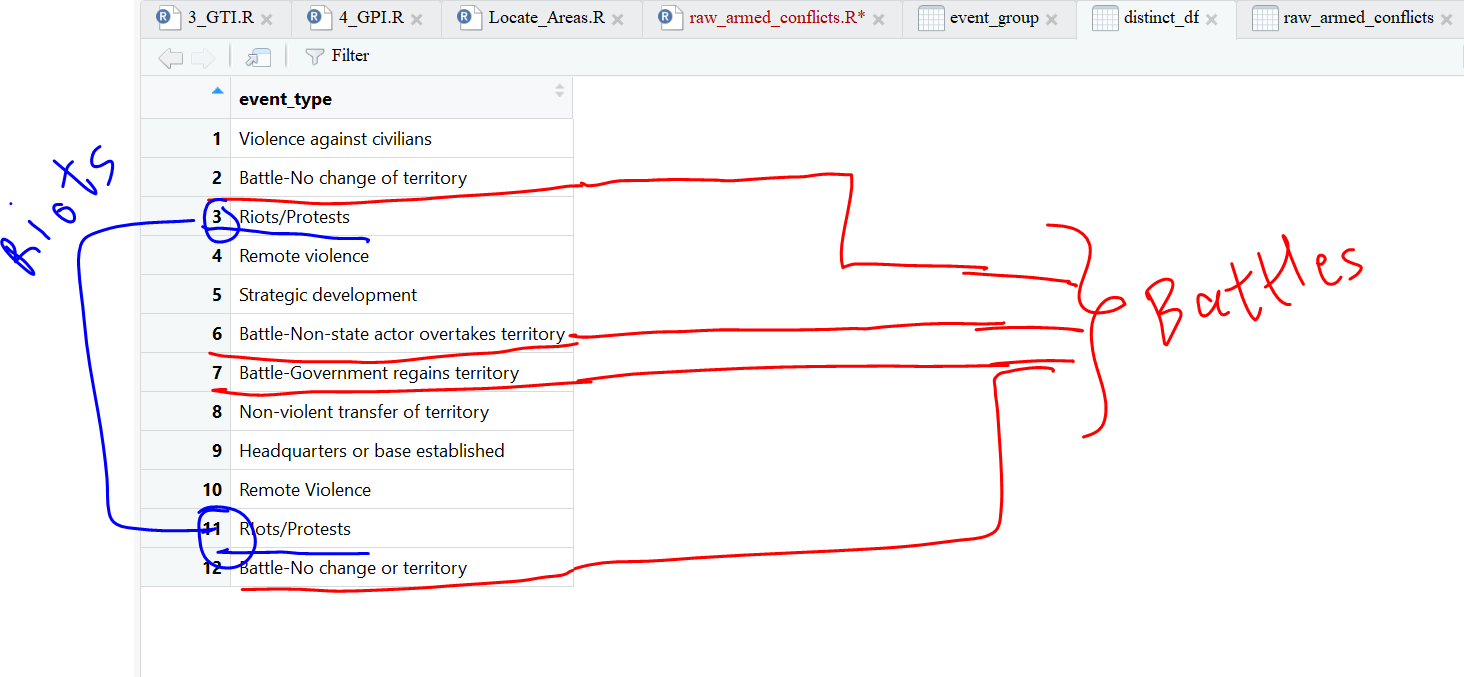
mutate(event_type = case_when(
str_detect(event_type, "Battle") ~ "Battles",
str_detect(event_type, "Riots") ~ "Riots",
TRUE ~ event_type
))
#> # A tibble: 18 x 10
#> data_id event_date year event_type region country iso3 latitude
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1892808 20-Oct-18 2018 Battles Easte… Burundi BDI -2.8772
#> 2 1892831 20-Oct-18 2018 Violence … Middl… Camero… CMR 5.9333
#> 3 1892860 20-Oct-18 2018 Battles North… Egypt EGY 31.1316
#> 4 1892861 20-Oct-18 2018 Battles North… Egypt EGY 31.2163
#> 5 1892874 20-Oct-18 2018 Strategic… Easte… Ethiop… ETH 12.9667
#> 6 1892875 20-Oct-18 2018 Violence … Easte… Ethiop… ETH 10.15
#> 7 1892920 20-Oct-18 2018 Battles Weste… Mali MLI 14.795
#> 8 1892921 20-Oct-18 2018 Violence … Weste… Mali MLI 16.6314
#> 9 1892922 20-Oct-18 2018 Riots Weste… Mali MLI 16.8425
#> 10 1892961 20-Oct-18 2018 Violence … Weste… Nigeria NGA 12.1492
#> 11 1892962 20-Oct-18 2018 Violence … Weste… Nigeria NGA 11.4953
#> 12 1893075 20-Oct-18 2018 Non-viole… Easte… Somalia SOM 3.0399
#> 13 1893076 20-Oct-18 2018 Riots Easte… Somalia SOM 8.4064
#> 14 1893282 20-Oct-18 2018 Violence … South… Afghan… AFG 33.6457
#> 15 1893283 20-Oct-18 2018 Violence … South… Afghan… AFG 34.5195
#> 16 1893284 20-Oct-18 2018 Strategic… South… Afghan… AFG 34.9145
#> 17 1893285 20-Oct-18 2018 Violence … South… Afghan… AFG 34.3448
#> 18 1893286 20-Oct-18 2018 Battles South… Afghan… AFG 34.5167
#> # … with 2 more variables: longitude <chr>, fatalities <chr>
Created on 2018-10-30 by the reprex package (v0.2.1)
 i am new to R and am happy that your well explained solutions are helping me develop more interest in it. Thanks again
i am new to R and am happy that your well explained solutions are helping me develop more interest in it. Thanks again