Hi, We are supplied data from an external supplier as csv files. Unfortunately the occasional record in some of the text files has an embedded line feed character in it. This makes loading it into a DB problematic. The supplier isn't able to fix the problem.
I was hoping there was some code I could write that would:
Load the whole record as 1 string - could be several thousand characters long
Scan the string for Line Feeds and replace with a space or a dot/full stop.
I am guessing that this may mean that the record delimiter is damaged ie the CR/LF is left as just CR??
If that is the case, could the code look for the LF but only do a replace where the character next to the LF is NOT a CR.
This strikes me as something R would be particularly well suited for.
Base R has a number of tools for detecting and handling strings, including special characters. I use the Tidyverse's stringr for these types of operations.
A good path forward would be to create a reproducible example of your data. I'd include in that example that has a few lines of the the special characters you are working with. That would make a great starting off point for folks here who'd like to offer suggestions. If you aren't familiar with reproducible examples, and setting up example data, here's a nice discussion with some options. (I often just use dput.)
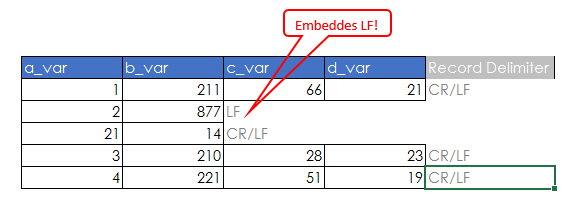
Hi, Thanks for your reply. In terms of example data, hopefully the following should help people understand what I am trying to do.
Somehow, a LF (Linefeed) has appeared in record 2 in c_var. This has meant the record is "broken" and the second part of the record shifts down to the next line.
I am hoping that there is some code I could use in R that will delete the extra LF without removing the LF in the actual record delimiter.
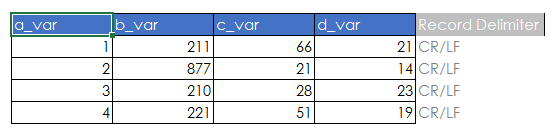
The following is how the data should look. I have greyed out the CR/LF characters as they wouldn't actually be seen when reviewing the data.