EDIT: I HAVE FOUND THE SOLUTION, SEE BELOW.
shared_conflicts <- df %>%
group_by(dispnum) %>%
filter(n()>1)
Hi there,
Apologies if this is a bit of a stupid question or if I've not used the correct terminology but I'm very new to this stuff. In fact I've reworded this whole box many-times so I'm hoping it actually makes sense.
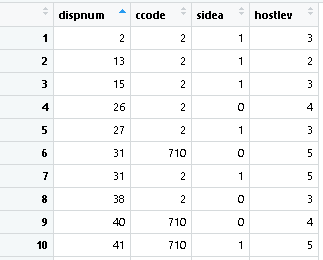
The data-set I am using is very large. Its purpose is to show conflicts between countries. I will note what the columns are called and what they mean.
- dispnum - the unique dispute identifier code. (i.e. if two rows have same dispnum it means they were in the same dispute)
- ccode - numerical code for countries, for my purposes I am looking at USA (ccode == 2) and China (ccode == 710)
- sidea - which side the country was on within the dispute (e.g. if this was WW2, UK = 0, GER = 1 meaning they were on opposite sides)
I want to produce a new data-set which removes all of the rows where the dispnum is unique (i.e. not shared by another row).
The end goal is to basically show if the number of disputes between US-China has increased/decreased over the years but need to get through this stage first! Where it is such a big dataset I'm trying to do this in the easiest way possible. A screenshot from the set is below and as you can see there are two rows which have the same dispnum. I would ideally just like to produce a new sheet which shows only those two rows which have the same dispnum (or something along those lines...) is it possible?