I am trying to read an excel file, where some cells' values start with 0s.
I tried the following. Unfortunately, the zeroes vanish away.
read_excel("data/example.xlsx",
col_types = c("text"))
I am trying to read an excel file, where some cells' values start with 0s.
I tried the following. Unfortunately, the zeroes vanish away.
read_excel("data/example.xlsx",
col_types = c("text"))
I tried the code using a mock Excel file modelled on your screenshot and I was not able to reproduce the error (i.e. it read the columns as strings and thus kept the leading zeroes).
Try appending readxl:: to your code, i.e.
readxl::read_excel("data/example.xlsx",
col_types = c("text"))
It might be that read_excel is from some other library and thus acts differently - doesn't hurt to try at least.
Can you provide some additional context to the problem?
I can reproduce the problem as follows. I made one column with text entries consisting of digit characters with leading zeros, e.g. 000012345, and another column with numeric entries formatted to pad with zeros on the left so that the number always had five digits. I used the Zip Code formatting to do this. Reading the file with
readxl::read_excel("A.xlsx", col_types = "text")
kept the leading zeros of the text column but dropped the leading zeros of the numeric column left-padded with zeros.
@Equation Thanks for your reply. I tried adding readxl::, still the same story.
@FJCC Thanks for trying out and reproducing the problem.
Based on @FJCC's answer, I would suggest that you do some initial formating in your Excel sheet, i.e. format the column as text (in Excel) - you should then be able to properly import it in R.
Yes, that is indeed a possible solution. But, I wonder if there is any way to avoid this manual work.
Well, you can format the column in R so that it is left-padded with zeros, but the column type will then be character, which will be inconvenient if you want to do math with the column. In this example, I manually construct the data frame but you would import it with read_excel() instead.
DF <- tibble::tibble(Number = c(1, 12, 123, 1234, 12345))
DF$Number = formatC(DF$Number, width = 5, flag = "0", format = "d")
DF
# A tibble: 5 x 1
Number
<chr>
1 00001
2 00012
3 00123
4 01234
5 12345
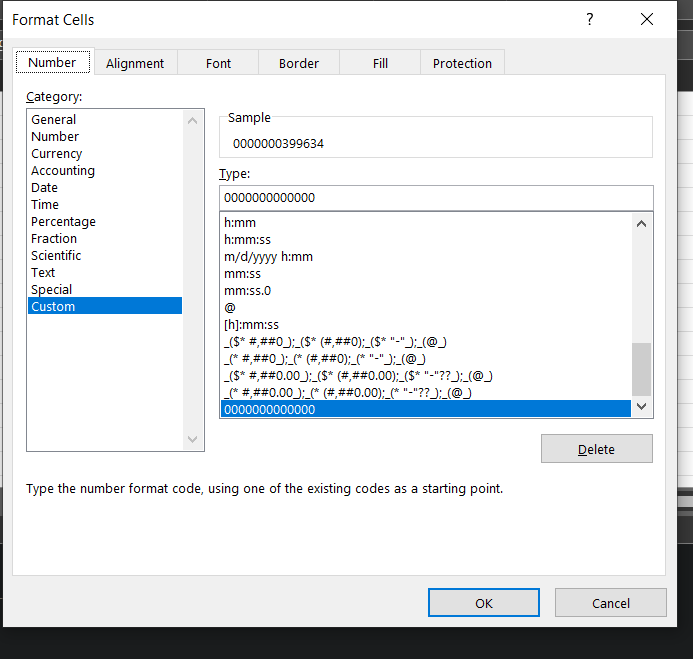
The Zip code format in Excel is internally represented as a number. So the zeroes are in the display, but not in the actual underlying data. If you tried to copy and paste as values in Excel, the leading zeros will go away and you will be left with just the number i.e. 00123 becomes 123.
I think that that means that what you got is the expected result?
I won't claim I expected the result but I suspected that was the root of the problem. I would not bet more than about $0.25 on the relationship between a spreadsheet's display and how it will treat the value.
@FJCC Thanks again. Actually, I will not do any math with those. I will use them for SQL queries. Sadly, they are not of the same length. So padding zeroes will not work here.
If you want to have a try, here is the example file: Dropbox - example.xlsx
I wrote a little function to pad the entries If they have fewer than 13 characters, which seems to be the effect of the formatting applied in Excel. I would have thought there would be a more direct way to do this in R but I ran into all sorts of problems with formatC() or using ifelse(). I don't know that this method is any less work than changing the Excel file directly.
library(dplyr)
DF <- readxl::read_excel("~/../Downloads/example.xlsx",col_types = "text")
DF
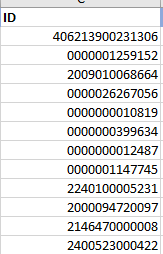
# A tibble: 12 x 1
ID
<chr>
1 406213900231306
2 1259152
3 2009010068664
4 26267056
5 10819
6 399634
7 12487
8 1147745
9 2240100005231
10 2000094720097
11 2146470000008
12 2400523000422
Func13 <- function(STR) {
for (i in seq_along(STR)) {
if(nchar(STR[i]) < 13) {
STR[i] <- paste0(strrep("0", 13 - nchar(STR[i])), STR[i])
}
}
return(STR)
}
DF <- DF |> mutate(ID = Func13(ID))
DF
# A tibble: 12 x 1
ID
<chr>
1 406213900231306
2 0000001259152
3 2009010068664
4 0000026267056
5 0000000010819
6 0000000399634
7 0000000012487
8 0000001147745
9 2240100005231
10 2000094720097
11 2146470000008
12 2400523000422
When I downloaded this spreadsheet, it has the same problem as zip code formatting. This is a number formatting, not a text formatting, so the leading zeros aren't actually in the data, just the formatting. You can tell this is the case by doing =istext(A3) in the spreadsheet.
Now, regarding how you might fix it, I think @FJCC 's solution is the most effective. You need to count the characters of each value in the column, and if a particular value has fewer than 13 characters, pad it with zeros until you get there. Depending on how you get the file, you could ask whoever prepares it to ensure that column is formatted as TEXT in Excel.
@FJCC and @dvetsch75 Many thanks for your effort! When I save the file as a text file, readr::read_delim() reads it perfectly.
This topic was automatically closed 21 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.