I am running RStudio Connect version 1.7.4.1-7 with R 3.5.1 on an EC2 instance. For my shiny apps I'm reading large feather files, my largest being almost 2 GB. When I read the files locally, feather is by far the fastest but when I read from the server feather files take more than 7 times what they do locally and RData and Rds are faster. Below are the run benchmark times for local and on the Connect Server.
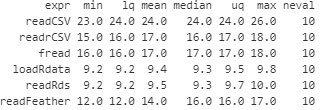
Local Results, Feather is
expr
min
lq
mean
median
uq
max
neval
readCSV
13
13
14
13
14
16
10
readrCSV
5.1
5.2
5.7
5.4
5.9
7.5
10
fread
1.8
1.8
1.9
1.9
2.1
2.3
10
loadRdata
7.3
7.4
7.6
7.5
7.7
7.8
10
readRds
7.3
7.4
7.5
7.5
7.6
7.8
10
readFeather
1.3
1.3
1.7
1.5
1.8
3.6
10
Here are the results run from Connect, which includes pulling the file from S3:
In the logs I do see that I frequently get the following error:
These 3 issues seems to be somewhat related to what I'm seeing but it sounds like an issue with feather files and it appears they will likely not be resolved.
Because all my apps have fairly large data sets I'm hoping I can find a solution that get's me much closer to that 1.7 avg. read time that I see locally. 14 seconds is not ideal for the end user experience. Any thoughts on this would be appreciated!
When you want to work with larger datasets inside a Shiny app, we generally recommend investigating other options, including:
Put your data inside a database, then bring into memory only the rows you need
Create aggregated summaries with a scheduled R Markdown, then read the aggregations into your shiny app
Use caching, memoisation and shiny promises to at least maintain responsiveness to other users
Read the data only once, in the Shiny app global scope, and use a Shiny reactive poll to refresh the data as necessary
In your specific case, you may also want to investigate downloading the feather file to the local machine, then importing from local, instead of over the network.
I haven't investigated the DB option but that may be a future path.
I'm currently aggregating and filtering the data as much as I can with scheduled R markdown, putting the data in S3 and reading those aggregations from S3. (we have a lot of data).
I've researched caching/promises etc. it seems like I'd have to fully revamp my code to use promises so I haven't done this yet this is potentially a solution.
I am reading in the data globally and use reactive poll to refresh the data but it still takes ~20-30 seconds for subsequent users to load the app, so this hasn't helped with time a ton.
Can you clarify the last piece? If I download the feather file locally, wouldn't that be the same as using output files from my Rmarkdown ETL process instead of pushing them to S3? This means storing a copy of all my data on the server instead of elsewhere or are you saying temporarily copy it locally, read the file and remove it. Am I understanding this correctly or not?
Yes, that's my suggestion. If I understand your benchmarks correctly, then reading the feather file from the local file system is relatively fast, but very slow from S3.
So my suggestion is to download the file in the background, read it and discard it once done. You should be able to do the download part asynchronously (using promises), if you design the app carefully.
Also, regardless of how large your data is, I suspect that any specific user is most likely only looking at a portion of that data at any given time. You should consider whether you can use a database to retrieve only the portion the user cares about at that time, rather than reading all of it for every user.
You said the largest feather file is 2 GB. How large is the corresponding RDS file? I have the impression that most of the time for feather files is spent on downloading the data, since RDS files are compressed and feathre files are not.
@cderv thank you for pointing out those other two options I will look into it and add those to my benchmark. I'll share results here, hopefully can dedicate some time to testing that out in the next few days.
@andrie I will look into the promises piece/downloading the file in the background and see if that could be a solution. The database option is definitely something I could do in the future as that would be a more ideal solution, just more time consuming to setup up front.
@rstub the RDS file is about a quarter of the size. I understand these are compressed but they typcially read much slower which is why I went with feather. I'd like the S3 read and download to be closer to the time it takes to read adn download a file that large locally, i.e. ~ 2 seconds.
Thank you all for your ideas and feedback, I will hopefully test some things out this week and report back hear. Appreciate the help!
Quick update, I've been trying to get a test to deploy to RStudio Connect for reading fst files from S3. I'm getting the following error when I deploy to connect. I tried changing all factors to characters in my data frame and still get this error when I move to connect. It works locally, performance isn't better locally but it might be on the server, if I could get it to deploy.
09/04 13:49:01.855
Error in `levels<-`(`*tmp*`, value = as.character(levels)) :
09/04 13:49:01.855
factor level [8] is duplicated
I then went on to try the new arrow package. Again slower locally but I cannot get this to deploy to connect. I tried including the Rcpp library, not including it and also adding the arrow::install_arrow() but I still get the error message below.
Additionally, I did go through the tasks outlined in this document https://arrow.apache.org/install/ to get the necessary libraries installed on our Connect server. Still no luck.
@rstub, that would be great, but it only provides a way to read parquet so I would need to find a way to write the parquet files from Connect in my ETL. I'll continue to research options, thank you for pointing this out.
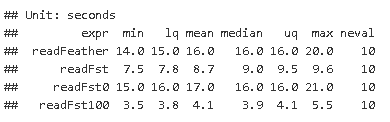
I wanted to share an update. I got FST files to work on connect. I compared 0 compression (readFST0), 50 compression(default, readFST) and 100 compression (readFST100) to feather. It appears using maximum compression I can read files about 4 times faster. I will look to implement this in my shiny apps and do additional profiling to measure load time improvement. Thanks for the help on this, I'm hoping this will be a significant improvement for the mean time.
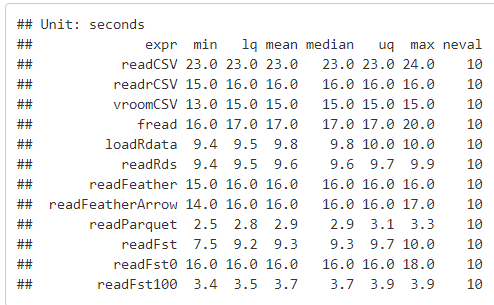
Even though this thread is old I thought it would be worthwhile to share the updated benchmarking I was able to do. After watching Neal Richardson's talk at RStudio Conf - I was hopeful I could finally get apache arrow deploy to RStudio Connect. With the new version on cran as of Friday, I was able to do a benchmark with arrow readFeather and arrow readParquet. It appears parquet is the fastest option with fst compresed to 100 the second best option.
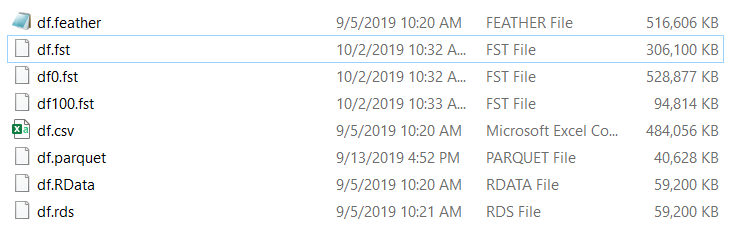
For reference, these are the associated file sizes in each format: