Hi. I have various Excel reports that that i have to do some analysis on. I pretty much figured out how to extract all the information I need, but my biggest concern is the accuracy of the numbers that gets read from Excel. The values seems to be converted to scientific notations and therefore the values gets rounded it seems. I can provide a sample file, just not sure how to submit the file.
Which package did you use to read the Excel data? There are usually options about how to handle data types.
I used readxl, read_excel function.
I must admit, the Excel file is very poorly formatted, so it is difficult to specify column types upfront
Ok, I would have thought that specifying e.g. col_double() would work if you had a column with just numbers.
Have you got characters in the problematic columns, too? These may be causing the numbers to be read in scientific notation.
This may help:
http://readxl.tidyverse.org/articles/cell-and-column-types.html
Unfortunately the sheet contains a header section, then some data, but there is also a movement row in between for every entity, and opening balance, closing balance, and then a footer with the grand totals. Difficult to explain, but very messy. Thanks for the link, will have a look.
Just for interest sake. There's also merged cells and what not.
I pretty much figured out the layout, and can extract all the info I need, it is just the formatting of the values that is still messing me around. Hopefully I can get some answers out of that link you send. Thanks
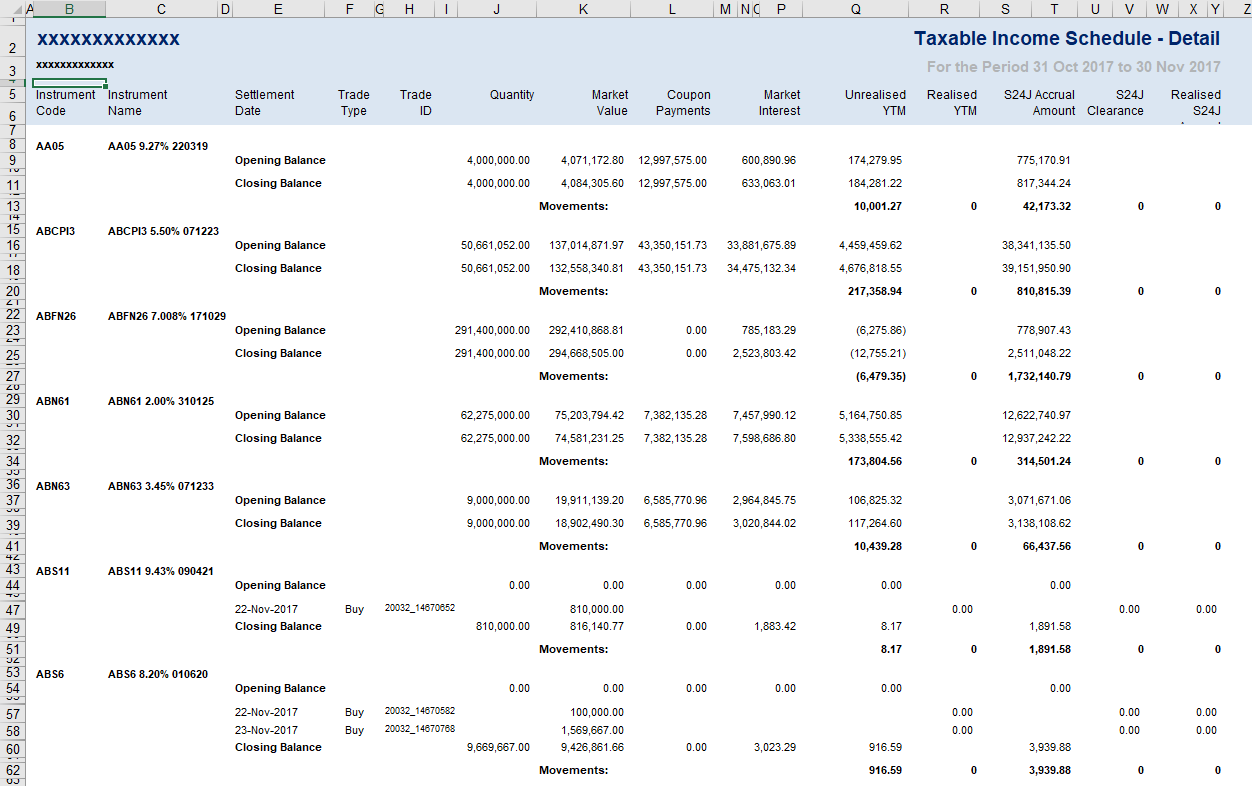
Ouch. I think this one requires input from @jennybryan.
Ouch indeed... I'm going to try a few things, like reading the file and specifying the types as numeric, then read it again as text to get the correct rows where the totals are, and then somehow join the two datasets
You should be able to define the separate ranges of the data (the structure appears consistent) and then use something like dplyr::bind_rows() or purrr::map(): to combine them
http://readxl.tidyverse.org/articles/sheet-geometry.html
http://readxl.tidyverse.org/articles/articles/readxl-workflows.html
At a high level, this sounds like a good plan for this sheet. Another extreme is to go all the way to tools like tidyxl, which will give you low-level data (one row per cell).
If you can't make any progress, let me know what sorts of numbers are the problem, whether the cells are numeric vs. text in Excel, and which variable type you're using on the R side.
I managed to get it working, messy, but the values tie up. I basically read the file twice, once as text, and once as numeric, and then combined the two with bind_cols(). Thanks for the help and suggestions.
That sounds ugly, but very plausible. Glad it worked out!
I should also point out the "list" column type might be helpful for columns with numeric and character data. There might be a workflow that allows you to ingest in one read, but that convenience might be negated by other wrangling you need to do.