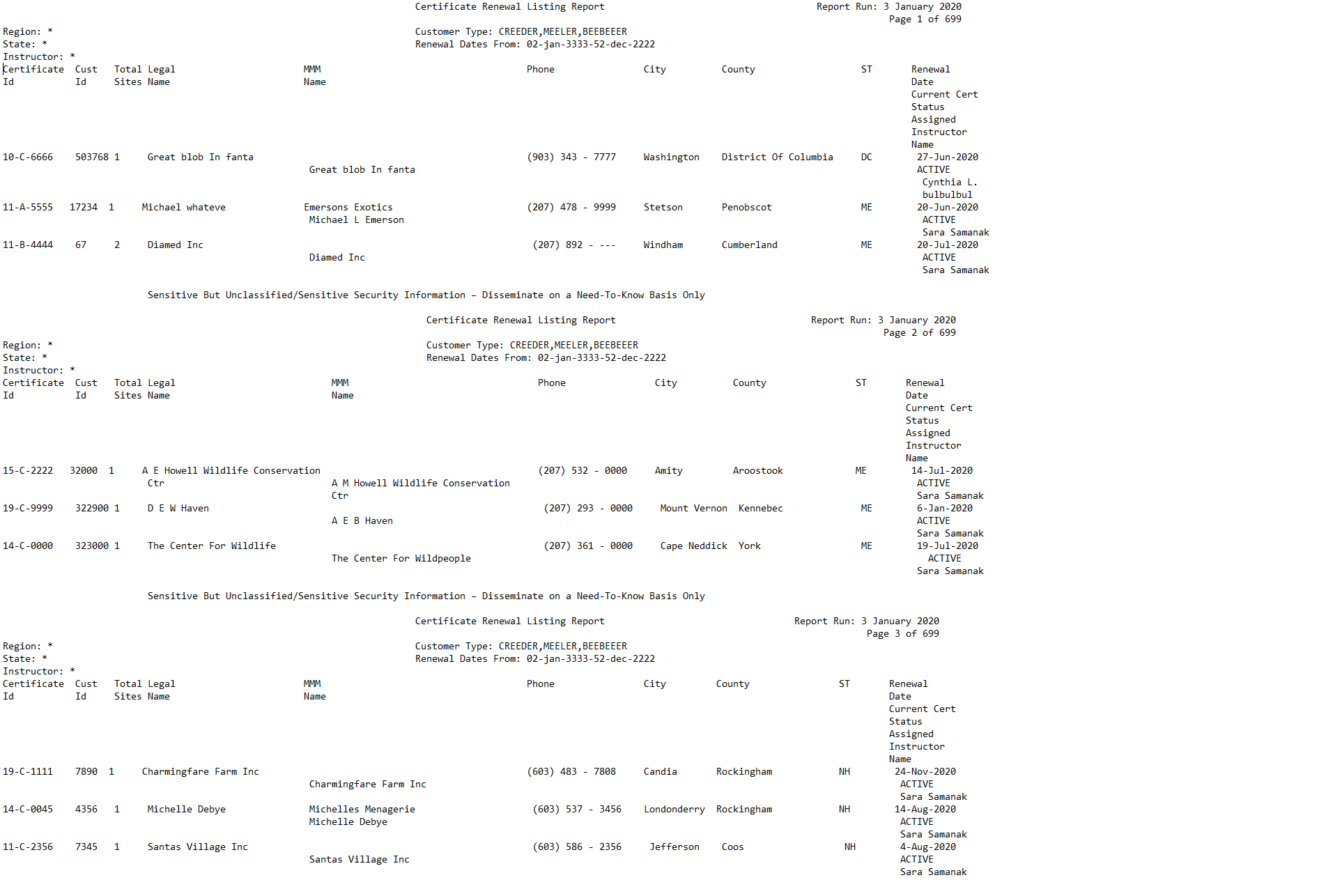
I'm having trouble thinking about the approach on reading a text file. I initially had a PDF file (700 pages worth of table formatted same exact way) which I then converted to a .txt file using the pdftools package.
The text file I end up getting has a bunch of texts (comments) that are not needed and then the table of 8 records and then it repeats itself on and on (see attached file).
I would read the whole thing into a dataframe using readr::read_csv and tidy it up from there.
If the formatting is irregular, though, it might be easier to read it in using df <- tibble(lines = readLines()) and then use regex and stringr to normalise and split it.
As woodward said you would have to read the data as it is and clean it with regular expressions, see this example (Obviously not a complete solution because honestly, this is going to be a little tedious)