Hi friends,
I'm using RStudio Cloud. Why can't I use the read_csv() function to import a dataset that I've uploaded in my current working directory, even though the necessary packages have been loaded?
library(readr)
library("readr")
#step 2: import data
#hotel_bookings.csv has been uploaded
bookings_df <- read_csv("hotel_bookings.csv")
Error: 'hotel_bookings.csv' does not exist in current working directory ('/cloud/project/Wk 3 Working with data in R').
I can only do it by left-clicking the file in the Files plane and selecting "Import Dataset":
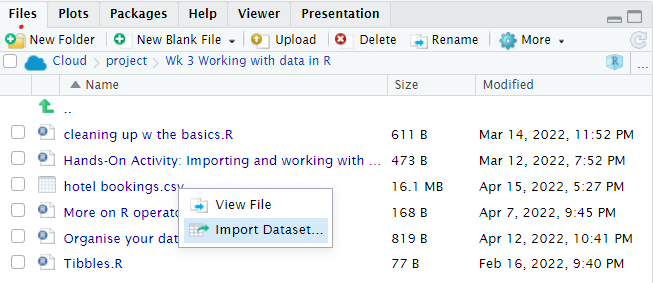
After which, the following codes automatically appear in my console, and not in my script (and thus, I cannot create a reprex for the following lines of code):
> library(readr)
> hotel_bookings <- read_csv("hotel bookings.csv")
Rows: 119390 Columns: 32
── Column specification ────────────────────────────────────────────────────────────────
Delimiter: ","
chr (13): hotel, arrival_date_month, meal, country, market_segment, distribution_ch...
dbl (18): is_canceled, lead_time, arrival_date_year, arrival_date_week_number, arri...
date (1): reservation_status_date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
> View(hotel_bookings)
Oh, now that I've used the code formatting button in the text editor for the 2nd paragraph of codes above (the first paragraph was done using reprex), can I also quickly check: is using a reprex equivalent to using the code formatting button of this text editor? If it is, I'll just stick to the latter as it's much faster.
Many thanks in advance! ![]()