I have mapped an area using object-based image analysis. This has resulted in 2000 image objects (polygons) that I want to classify based on their properties (spectral, RGB data, shape, size etc.).
I have saved the data as a .csv for use in 'Randomforest' package.
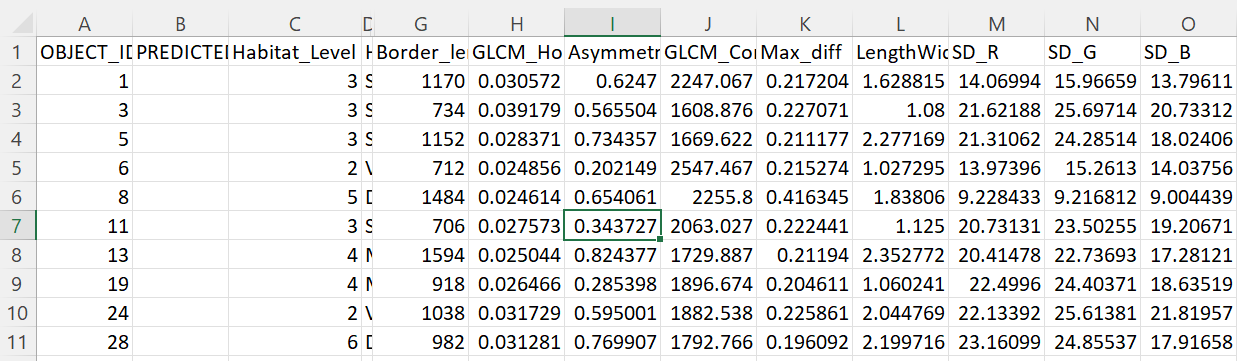
I have assigned "Habitat Level" as one of six factors for each object in the data (1, 2, 3, 4, 5,6). Example of the csv attached.
What I want to do is run randomforest to assign a "Habitat_Level" each of the image objects (Column: OBJECT_ID).
So the result I need will fill the "PREDICTED" column with "Habitat_Level" (generated from random forest) that uses the OBJECT_ID to discriminate between objects.
I have run the randomforest but I don't know how to assign the classification to existing OBJECT_ID
Do you need help getting the data into R or using the randmForest package?
Also, it is worth mentioning that giving a randomForest model a data set, then re-predicting it will almost certainly give you the same results back. For these types of models, you usually use existing data to predict new data.
Imagine giving a bunch of students a test to memorize. After that, give them the same test to evaluate their knowledge. The results from the knowledge is unlikely to reflect anything meaningful.
I think for sure I have made some progress with regards to this data set and randomForest classification model.
I wasn't very clear in my original response, also. I have subsetted my entire data set (2000 odd objects, 20 variables) into training and testing data (total 200 odd objects).
My training data will be used to construct the model, then tested on the test data.
Further to that, based on what model is the most accurate - I will be predicting Habitat_Class for the rest of the data.