We’ve been using future_map (from the furrr package) to run some modeling code in parallel. Our timing runs have produced some odd results (details below). We’re not really sure what to try next at this point, so I’ll welcome suggestions.
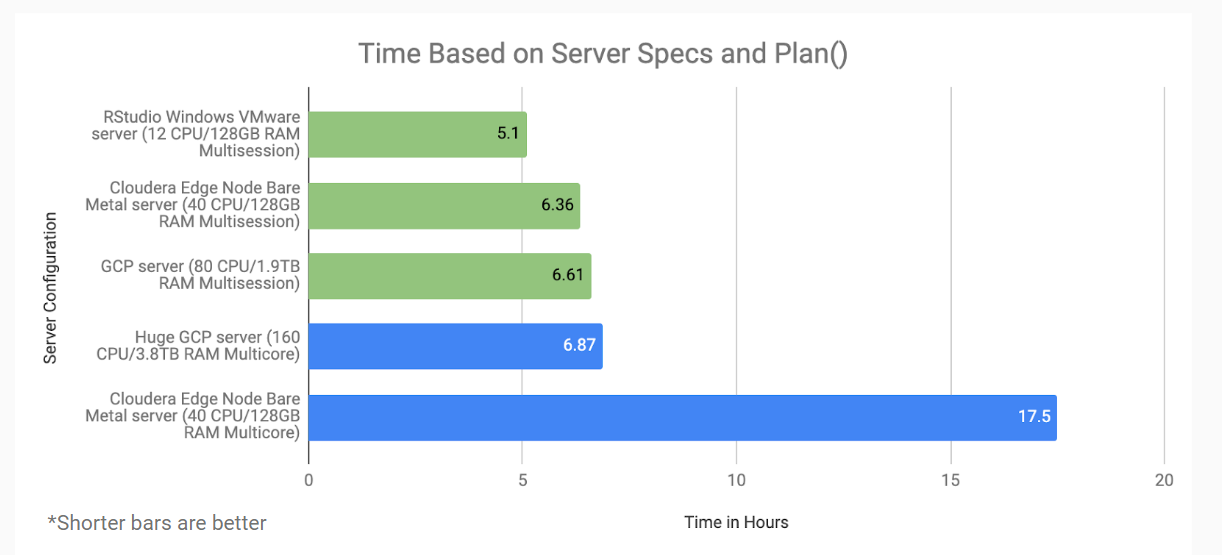
Initially the modeling code ran in 5 hours on an in-house VM with 128 GB of RAM and 12 cores. We then tried the same data and code on a Google Cloud Platform with a variety of more powerful setups (both additional cores and additional RAM) and every single run took longer. We also tried adding more RAM to the same VM (up to 256 GB from 128 GB) and the model slowed down from 5 hours to 7 hours. Mystified, we downgraded the VM back to 128 GB and the model went back to taking 5 hours.
A few weeks later our modeling slowed down drastically - unable to identify a reason we tested on the same code and data we’d used for timing runs before (we’d tweaked the modeling code a little and we get new data every month, so we wanted to eliminate those as possible reasons for the slow down). The modeling code went from 5 hours to 14 hours. It was 14 hours on both the same 128 GB VM and a different in-house 256 GB VM.
I’m wondering if anyone who knows more about hardware and/or more about future_map can give us some suggestions on what to try next. We’re mystified both by the initial finding that more RAM slowed things down and by the sudden slowdown of the same script on the same machine.
Timing from the initial test runs: