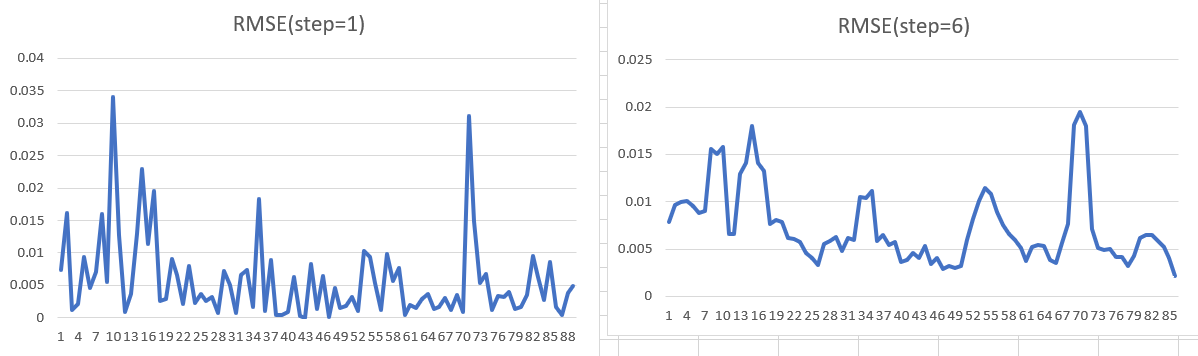
I am using the sliding_window() or rolling_origin() from resample R package . For the one-step-ahead forecast, I used assess = 1, and six steps ahead forecast assess = 6. First, I tune the models then passed these tuned models to fit_resamples() . Get the RMSE from these slices and plot against the time. However, the issue is that I get a larger RMSE at assess= 1 than assess = 6 which is counter-intuitive obviously it should be a larger RMSE at assess =6. I have given below reproducible codes with hypothetical data and graphs. I do not know what is wrong. Is there is an issue with my method? Please help.
library(Quandl)
library(tidymodels)
library(resample)
library(tidyverse)
library(lubridate)
library(timetk)
df1 <- Quandl(code = "FRED/PINCOME",
type = "raw",
collapse = "monthly",
order = "asc",
end_date="2017-12-31")
df2 <- Quandl(code = "FRED/GDP",
type = "raw",
collapse = "monthly",
order = "asc",
end_date="2017-12-31")
per <- df1 %>% rename(PI = Value)%>% select(-Date)
gdp <- df2 %>% rename(GDP = Value)
data <- cbind(gdp,per)
data1 <- tk_augment_differences(
.data = data,
.value = GDP:PI,
.lags = 1,
.differences = 1,
.log = TRUE,
.names = "auto") %>%
select(-GDP,-PI) %>%
rename(GDP = GDP_lag1_diff1,PI = PI_lag1_diff1) %>%
drop_na()
lag_period <- c(1:5)
data_pre_full <- data1 %>%
# add lags
tk_augment_lags(
.value = GDP:PI,
.lags = lag_period)
data_prepared_tbl <- data_pre_full %>%
dplyr :: select( -PI ) %>%
drop_na()
splits <- timetk::time_series_split(data_prepared_tbl, assess = 70, cumulative = TRUE)
recipe_spec <- recipe(GDP ~ ., data = training(splits)) #%>%
# *Resampling-----
resamples_tscv <- sliding_window(data_prepared_tbl,
lookback = 100,
assess_stop = 1, step = 2
)
plan_org <- resamples_tscv %>% tk_time_series_cv_plan()
plan_tr1 <- plan_org %>%
filter(plan_org$.key == "testing")
plan <- plan_tr1 %>% select(Date,.key,.id,GDP)
# * SVM ----
wflw_fit_svm <- workflow() %>%
add_model(
spec = svm_rbf(mode = "regression") %>% set_engine("kernlab")
) %>%
add_recipe(recipe_spec %>% update_role(Date, new_role = "indicator")) %>%
fit(training(splits))
# Fit resamples
keep_pred <- control_resamples(save_pred = TRUE, verbose = TRUE)
set.seed(20201024)
# Fit resamples
rf_res <- fit_resamples(wflw_fit_svm,
resamples = resamples_tscv, control = keep_pred)
rf_res
pr <- rf_res %>%
# grab specific columns and resamples
pluck(".predictions")
pred1<- rf_res %>%
# combine ALL predictions
collect_predictions()
pred_final1 <- cbind(pred1,plan)
write.csv(pred_final1, file = "pred.SVM1.csv")
# Summarize all metrics
rf_res %>%
collect_metrics(summarize = TRUE)
rmse <- rf_res %>% collect_metrics(summarize = FALSE)
rm <- rmse %>%
filter(rmse$.metric == "rmse")
write.csv(rm, file = "rmse_1.csv")