I am learning R programming. I need your inputs to fix the error which I'm getting in one of my R program. Request your help to resolve it. Thanks in advance
Question:
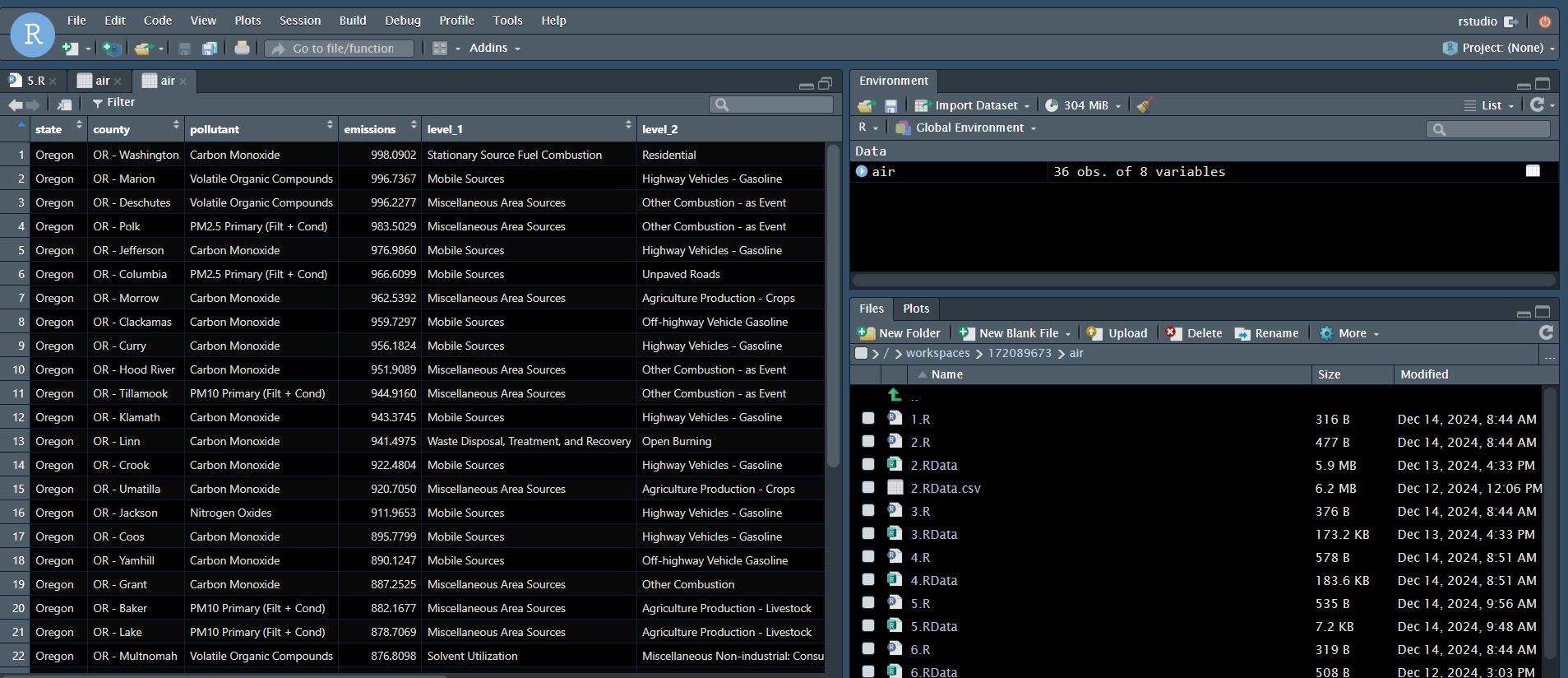
a) In 5.R, load the air tibble from air.RData with load. Transform the tibble so that it includes the single row with the highest value in the emissions column for each county.
b) Save the resulting air tibble, using save, in a file called 5.RData.
c) Executing 5.R should create a tibble named air with 36 rows and 8 columns, sorted from highest to lowest value in the emissions column
Your code is really hard to read. It is much better to copy the code and paste it here between
This gives us formatted code that we can copy, paste and run . Often a person here does not have the time to type out code to test it and find a problem.
That said, I think there is a space here between air and RData.
load("/workspaces/xxxxx/air/air. RData")
You may find this helpful in asking questions here..
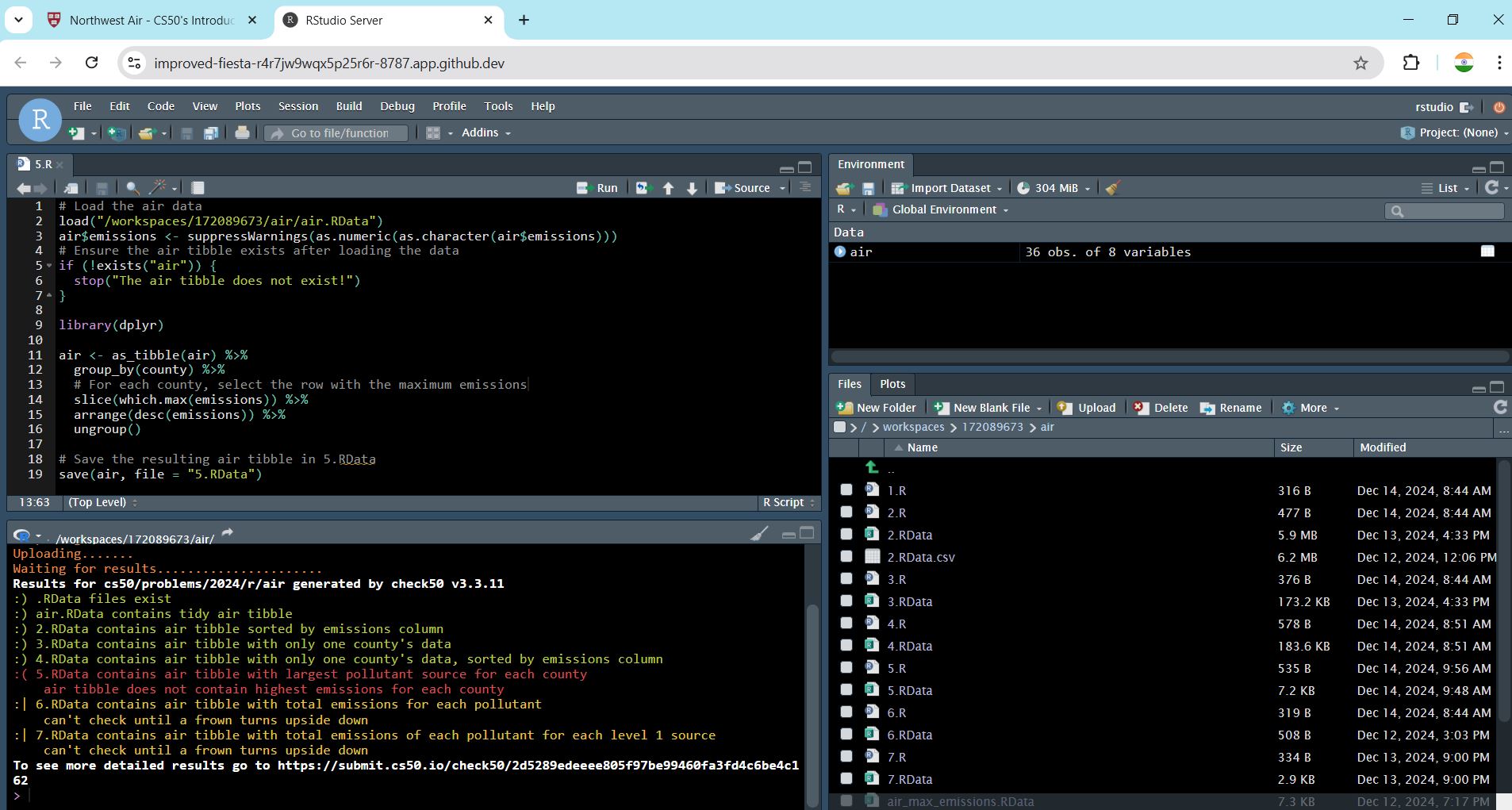
Thank you very much for your valuable time and reply. I have copy pasted my code in my original post. Also attached my output screen shot.
air.RData file has more than 32,000 records. My code filtered 36 relevant records with 8 columns out of total 32,000 records. However R throws error. I tried my level best to solve it but in vain.
Kindly help me resolve this issue. Thank you very much.
Thanks, it is much easier to read your code now. However there in an even better way to do it. I thought I had pasted in the instructions but it looks like I messed up the formatting. My apologies.
The best way to provide code is to copy it and paste it between
```
```
I think your code sequence is not optimal.
Let's try this bit of rearranged code and see what happens.
# Load packages. I am loading tidyverse. {dyplr} is part of it.-----------
library(tidyverse)
# Load data ---------------------------------------------------------------
load("/workspaces/xxxxx/air/air.RData")
# Check to see if air data.frame/tibble exists and check `emmissions structure ---
air
str(air$emissions)
IS that dataset you are using publicly available? If so I might download it.
You have your data in air.RData. Have you modified the variable names at all or done other manipulations to the the existing air.csv file. The original air.csv looks like one of those blasted Excel exports.
Just look at the variable names.
1: State
2: State-County
3: POLLUTANT
4: Emissions (Tons)
5: Pollutant Type
6: SCC Code
7: EIS Sector
8: Source Description
9: SCC LEVEL 1
10: SCC LEVEL 2
11: SCC LEVEL 3
12: SCC LEVEL 4
13: EPA Region
14: FIPS
Thanks, I am starting to see the problem. Somehow you have confused something inthe data reading & saving . Can you post the code you were using to read in the data and "save" it. We might find where the problem is.
The first thing to note in my list of names above is that there is no variable "emissions" . It looks like it is "Emissions (Tons)"
We need to clean up those horrible variable names and then save a new file. As far as I am concerned you do not want a RData file. Just keep everything as a .csv file. It's alot simpler and IMHO RData files are an anachronism.
ACH. I may be a while getting bark to you. Your project folder seems to have gotten corrupted I may have to rebuiltit.
I am still not sure what was happening but I think I have something that should help a bit. I am just getting you to the point where you have usable data. Remember though, there is no variable "emissions"; it is "emissions_tons".
# Load packages -----------------------------------------------------------
suppressMessages(library(data.table))
suppressMessages(library(tidyverse))
library(janitor)
library(here)
# Import data and tidy up name---------------------------------------------------------
dat1 <- read_csv("./raw_data/air.csv")
names(dat1)
dat1 <- dat1 %>% clean_names()
names(dat1)
# Save to new file at main project level file ----------------------------
write_csv(dat1, "air-rev.csv")
# Start what you were trying to do ----------------------------------------
air <- read_csv("air-rev.csv")
First of all we don't know for sure if you actually loaded the data. It looks like you did not but it's not completely clear. The message
"air.RData does not exist"
seems to indicate that you did not. Or you did successfully load the data but air.RData would not be the name of your dataset. It is the name of the storage file where the data is.
With out that code I don't think we can tell.
Second, if you did load the data all right, since you did not recode the variable names there was no variable "emissions" in your data set. That's what @ mduvekot was talking about.