Does the loop variable, lets say "i", have to be used in the loop body ? does the loop need a loop variable ?
it always has to be at least like this?; for (i in vector) { }
can it be something other than "i" ? but it can only be a single character ?
Does the loop variable, lets say "i", have to be used in the loop body ? does the loop need a loop variable ?
it always has to be at least like this?; for (i in vector) { }
can it be something other than "i" ? but it can only be a single character ?
I'm not positive if I'm getting what you're asking, but you don't need to name the loop variable i. It also can be more than 1 character.
Here's an example:
# looping variable can be i
for (i in 1:10) {
print(i)
}
#> [1] 1
#> [1] 2
#> [1] 3
#> [1] 4
#> [1] 5
#> [1] 6
#> [1] 7
#> [1] 8
#> [1] 9
#> [1] 10
# or it can be another single character
for (x in 1:10) {
print(x)
}
#> [1] 1
#> [1] 2
#> [1] 3
#> [1] 4
#> [1] 5
#> [1] 6
#> [1] 7
#> [1] 8
#> [1] 9
#> [1] 10
# or any combo of characters (assuming it begins with a letter)
for (look_at_all_these_characters_woah in 1:10) {
print(look_at_all_these_characters_woah)
}
#> [1] 1
#> [1] 2
#> [1] 3
#> [1] 4
#> [1] 5
#> [1] 6
#> [1] 7
#> [1] 8
#> [1] 9
#> [1] 10
I'm not sure what you mean by this part.
If you're using a for loop I think it needs a loop variable, though I'm not positive.
If you're using a for loop in R, the loop variable doesn't necessarily have to appear in the loop body, because the loop takes care of changing the loop variable to the next element in the provided list automatically. So something like:
for (counter in 1:10) {
print("Sup lol")
# no need to increment `counter`: it'll automatically change to the next
# element in 1:10 now!
}
Is totally fine: it'll print "Sup lol" 10 times. Contrast that to a while loop, where you have to ensure that either:
FALSE, based on what happens in the loop; orcontinue keyword inside the loop body to to stop it yourself.So something like:
counter = 0
while (counter < 10) {
print ("Sup lol")
}
... will just print "Sup lol" forever, because nothing changes the value of counter (and hence the loop condition is always TRUE).
Hope that helps!
# The vector `p` contains 100 proportions of Democrats ranging from 0 to 1 using the `seq` function
p <- seq(0, 1, length = 100)
# The vector `sample_sizes` contains the three sample sizes
sample_sizes <- c(25, 100, 1000)
# Write a for-loop that calculates the standard error `se` for every value of `p` for each of the three samples sizes `N` in the vector `sample_sizes`. Plot the three graphs, using the `ylim` argument to standardize the y-axis across all three plots.
for(i in sample_sizes){
se <- sqrt(p * (1 - p) / sample_sizes)
plot(x = p, y = se, ylim = c(0, sqrt(25)))
}
#> Warning in p * (1 - p)/sample_sizes: longer object length is not a multiple
#> of shorter object length
#> Warning in p * (1 - p)/sample_sizes: longer object length is not a multiple
#> of shorter object length
#> Warning in p * (1 - p)/sample_sizes: longer object length is not a multiple
#> of shorter object length
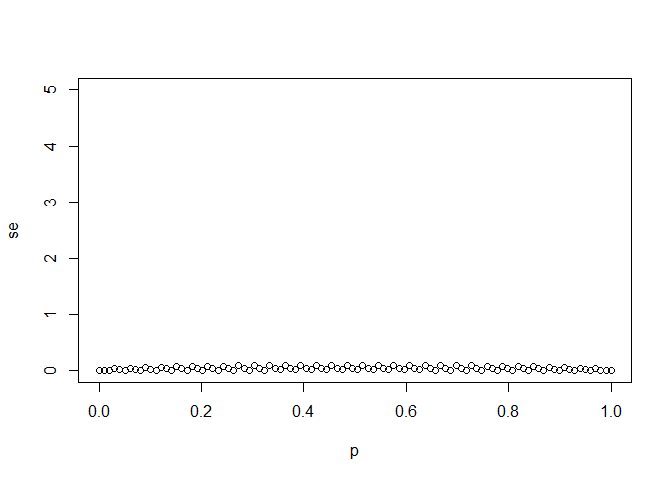
this code gave me what i wanted. its the first time (i think) where the loop variable (i) is not used in the loop body. whats the point of having a loop variable if its stored value is not used in the loop body ?
Hi:
You don't need the loop. What is happening is that R is making the same routine:
se <- sqrt(p * (1 - p) / sample_sizes)
plot(x = p, y = se, ylim = c(0, sqrt(25)))
three times. But you achieve the same result without the loop. The only thing the loop is doing is slowing the execution time.
So, to answer your last question.There is no point of having a loop if the index is not used in the loop (in general). Unless you want to slow the execution time xD
I still don't understand what do you want to do, but according to the comment
# Write a for-loop that calculates the standard error `se` for every value of `p` for each of
the three samples sizes `N` in the vector `sample_sizes`. Plot the three graphs, using the
`ylim` argument to standardize the y-axis across all three plots.
The code is not doing this. It is just recycling the vector 'sample_sizes' as it is shorter than the vector 'p'.
What you would need is something like:
p <- seq(0, 1, length = 100)
sample_sizes <- c(25, 100, 1000)
se <- list()
for(i in 1:length(sample_sizes)){
se[[i]] <- sqrt(p * (1 - p) / sample_sizes[i])
}
cheers
Fer
its a data camp exercise and it needs the submitted code to be as i have in the reprex. in the real world i guess it would be different. how is R doing it three times? because of the three values in the sample_size vector ? is having a loop variable in the constructor but not used in the body considered valid code or not ? how bout just a loop variable in the body but none in the constructor ?
Hi. It is doing three times because of the vector sample_size, as you said, but each time is doing the exact same operation.
I would not consider it valid. I mean, writting a loop without using it is not good. Here the time is not that important due to the small magnitude of the example, but it may be in other tasks (real example: I had some very old code with some routines that took ~30 min per individual, with ~200 individuals. When I went back to that code I found a messy loop doing nothing but repeating the same operation several thousands of times. Of course, the loop was propagated along the script, making it worst. Once removed, each individual process took 1-2 seconds)
Anyway, I don't think your apprach is valid, if you want to do the operation you wrote for each of the three values os sample_sizes,, you have to explicit it in a loop or using an *pply function for it.
What your code is doing is dividing the first (p(1-p)) by the first sample_size value, the second (p(1-p)) by the second sample_size value, the third (p(1-p)) value by the third and the fourth (p(1-p)) again by the first sample_size value and so on. R is recycling the vector sample_size as it is smaller than the vector p. So this is not what I think you are aiming.
Running the loop I coded above, and plotting it,, makes it looking more to what I think you are aiming:
Cols <- c('black','dodgerblue','firebrick')
plot(p,se[[1]], type = 'l', col = Cols[1],lwd = 2, xlab = 'p', ylab = 'se')
points(p,se[[2]], type = 'l', col = Cols[2], lwd = 2)
points(p,se[[3]], type = 'l', col = Cols[3], lwd = 2)
## legend
leg = paste('N = ', sample_sizes, sep = '')
legend('topleft', col = Cols, legend = leg, lwd = 2)
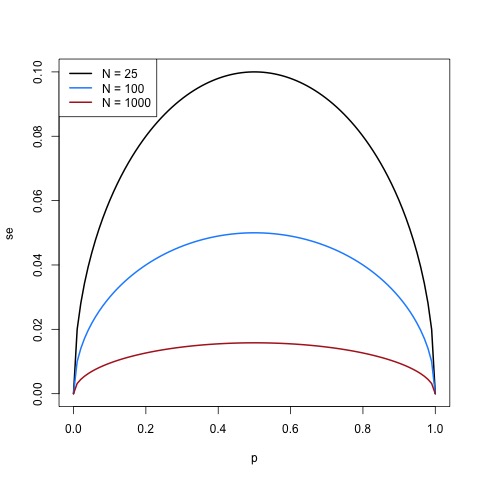
the SE got reduced as sample size increases
cheers
Fer