Hi there,
I have a data frame that has a "value" column, which is the value of an observation for each "group". I also have a "count" column, which is the number of time that value appears for each group. For example:
tibble::tribble(
~group, ~count, ~value,
"A", 2, 10,
"B", 1, 12,
"B", 2, 13
)
What I am trying to do is create a dataframe that duplicates the rows for each group / value combination, based on the count column. Kind of an "un-summarize". So the dataframe above would end up like this:
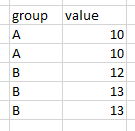
Seems relatively straightforward but I can't figure it out! Any help would be appreciated. (In case this seems like a strange task, the reason I am doing it is for visualization purposes).
Thank you!
Steve