Hi, I have this df
df
# A tibble: 248 × 2
asignado mxsitam
<chr> <chr>
1 Control No
2 Control No
3 Intervencion No
4 Intervencion Si
5 Intervencion Si
6 Intervencion Si
7 Control No
8 Intervencion Si
9 Control Si
10 Control Si
# ℹ 238 more rows
I want to make a table that includes a column showing the difference between percentages. The problem is that it does not calculate it for the values of the variables but for the variables themselves, and I do not understand what calculation it does.
This is the code.
df %>%
mutate_all(as.factor) %>%
tbl_summary(by= "asignado",
missing = "always",
digits = list(all_categorical() ~ c(0,1)),
statistic = list(all_categorical() ~ "{n} ({p})"),
missing_text= "Casos perdidos",
percent= "column") %>%
add_overall() %>%
modify_header(label = "") %>%
add_difference()
This is the output
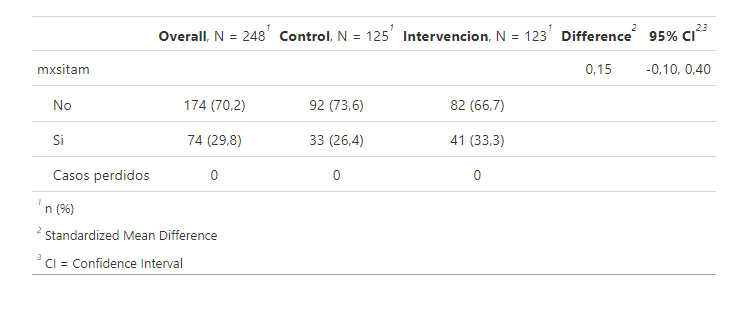
What I want is the difference between the Control and Intervention percentages, for example 73.6 - 66.7.
The strange thing is that with this code I have something more similar, but it does not show me for all levels and doesn't show me the CI.
df %>%
mutate(mxsitam= as.integer(if_else(mxsitam== "No", 0,1))) %>%
tbl_summary(by= "asignado",
missing = "always",
digits = list(all_categorical() ~ c(0,1)),
statistic = list(all_categorical() ~ "{n} ({p})"),
missing_text= "Casos perdidos",
percent= "column") %>%
add_overall() %>%
modify_header(label = "") %>%
add_difference()
