Hi,
So I was trying to replicate results from one of the papers in JDE.
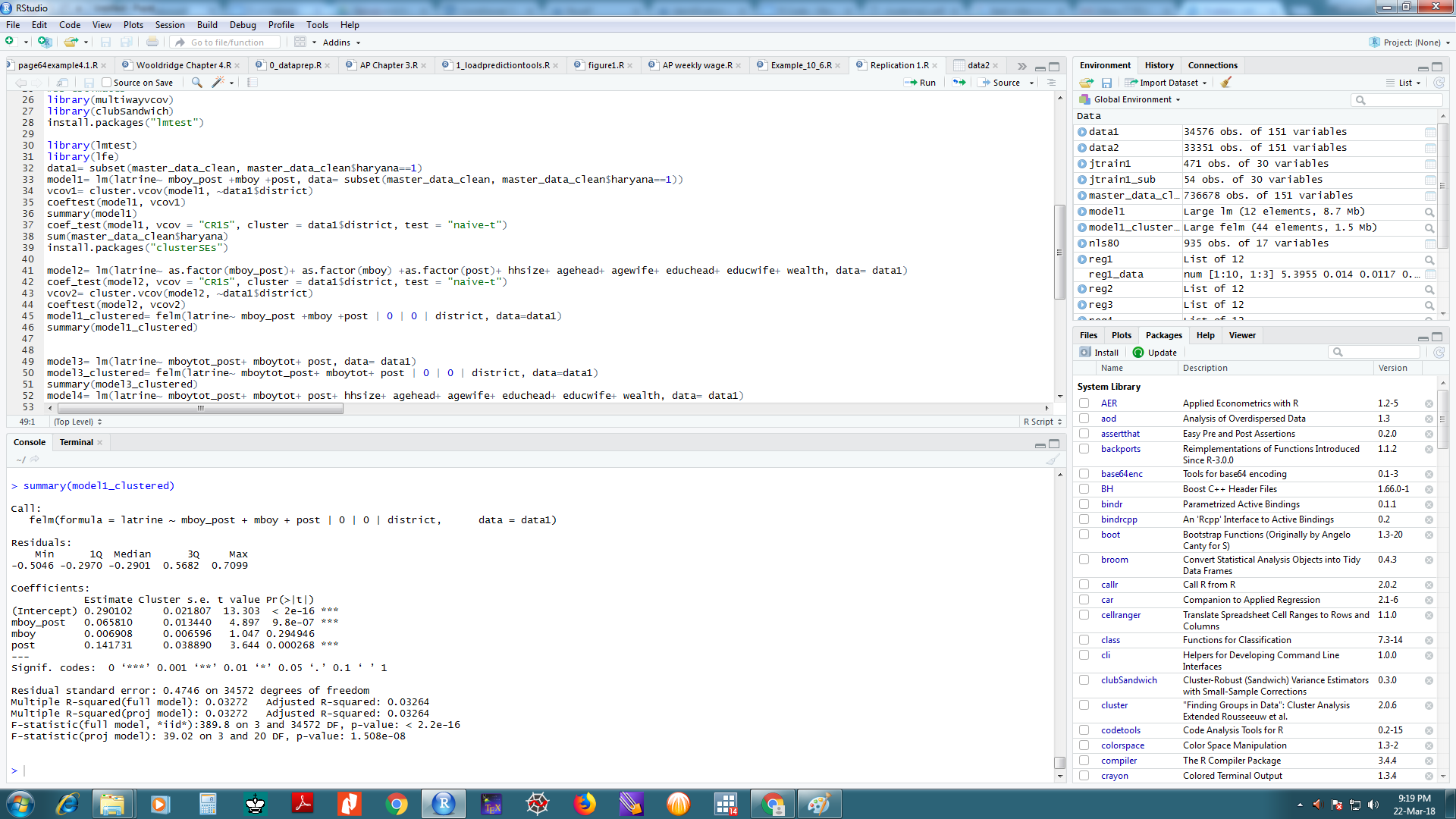
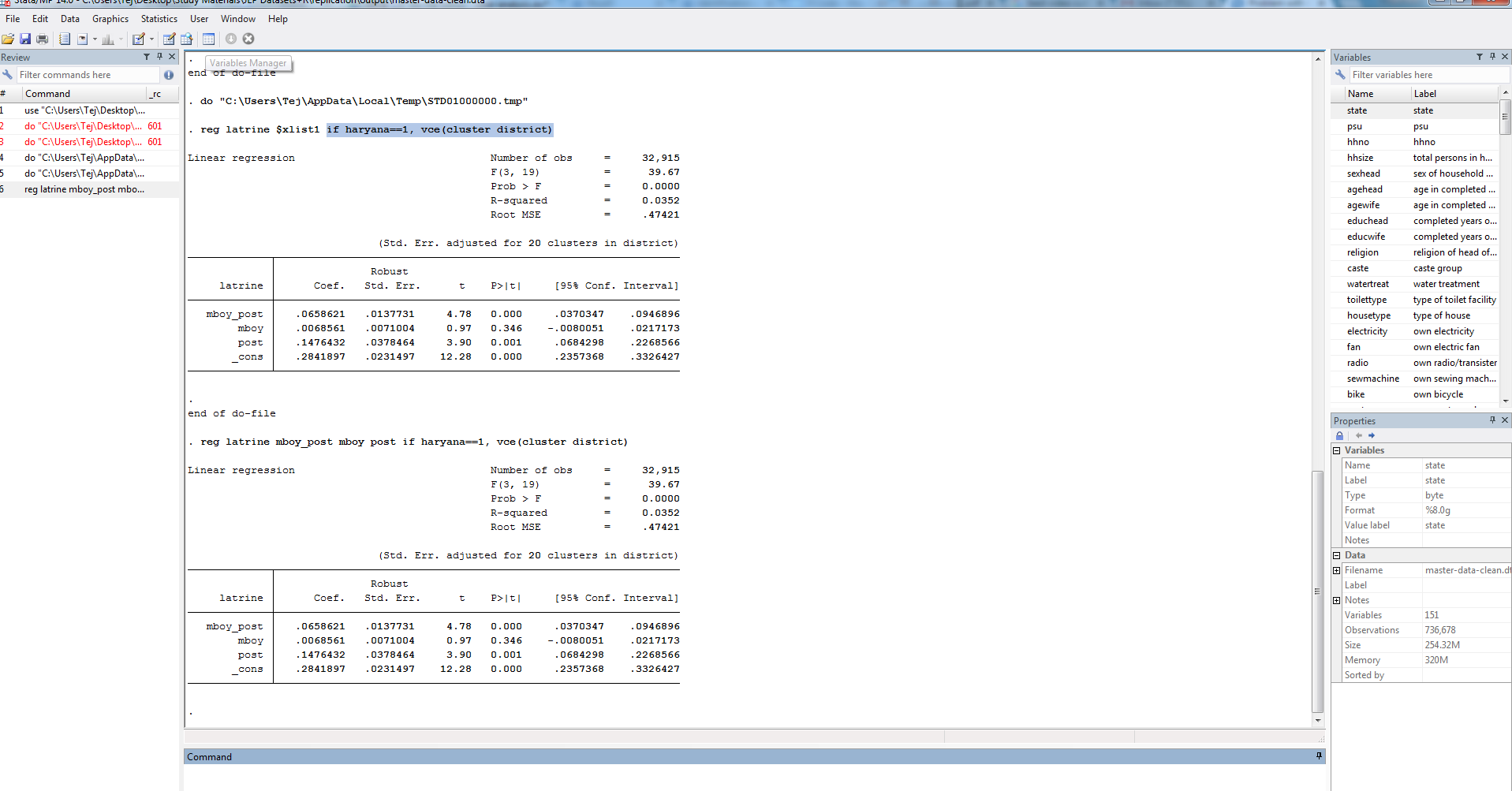
The thing is that when the data is analyzed in Stata, Stata fits the model and corrects for Clustered SE's on 32,915 Observations but R fits the same model and corrects for Clustered SE's on 34,576 observations.
Due to this there is a slight change in the estimated coefficients at 3rd or 4th decimal place.
I don't understand why there is a discrepancy in two estimates even when the mechanics of the correction in two software is same.
I am attaching the data set and results and codes in Stata and R.
Any help will be appreciated.
Could you please turn this into a self-contained reprex (short for minimal reproducible example)? It will help us help you if we can be sure we're all working with/looking at the same stuff.
library(lmtest)
#> Loading required package: zoo
#>
#> Attaching package: 'zoo'
#> The following objects are masked from 'package:base':
#>
#> as.Date, as.Date.numeric
library(lfe)
#> Loading required package: Matrix
#>
#> Attaching package: 'lfe'
#> The following object is masked from 'package:lmtest':
#>
#> waldtest
data1= subset(master_data_clean, master_data_clean$haryana==1)
#> Error in subset(master_data_clean, master_data_clean$haryana == 1): object 'master_data_clean' not found
model1= lm(latrine~ mboy_post +mboy +post, data= subset(master_data_clean, master_data_clean$haryana==1))
#> Error in subset(master_data_clean, master_data_clean$haryana == 1): object 'master_data_clean' not found
vcov1= cluster.vcov(model1, ~data1$district)
#> Error in cluster.vcov(model1, ~data1$district): could not find function "cluster.vcov"
coeftest(model1, vcov1)
#> Error in coeftest(model1, vcov1): object 'model1' not found
summary(model1)
#> Error in summary(model1): object 'model1' not found
coef_test(model1, vcov = "CR1S", cluster = data1$district, test = "naive-t")
#> Error in coef_test(model1, vcov = "CR1S", cluster = data1$district, test = "naive-t"): could not find function "coef_test"
sum(master_data_clean$haryana)
#> Error in eval(expr, envir, enclos): object 'master_data_clean' not found
install.packages("clusterSEs")
#> also installing the dependencies 'miscTools', 'bdsmatrix', 'maxLik', 'statmod', 'plm', 'mlogit'
#> package 'miscTools' successfully unpacked and MD5 sums checked
#> package 'bdsmatrix' successfully unpacked and MD5 sums checked
#> package 'maxLik' successfully unpacked and MD5 sums checked
#> package 'statmod' successfully unpacked and MD5 sums checked
#> package 'plm' successfully unpacked and MD5 sums checked
#> package 'mlogit' successfully unpacked and MD5 sums checked
#> package 'clusterSEs' successfully unpacked and MD5 sums checked
#>
#> The downloaded binary packages are in
#> C:\Users\Tej\AppData\Local\Temp\RtmpKa9qgx\downloaded_packages
model2= lm(latrine~ as.factor(mboy_post)+ as.factor(mboy) +as.factor(post)+ hhsize+ agehead+ agewife+ educhead+ educwife+ wealth, data= data1)
#> Error in is.data.frame(data): object 'data1' not found
coef_test(model2, vcov = "CR1S", cluster = data1$district, test = "naive-t")
#> Error in coef_test(model2, vcov = "CR1S", cluster = data1$district, test = "naive-t"): could not find function "coef_test"
vcov2= cluster.vcov(model2, ~data1$district)
#> Error in cluster.vcov(model2, ~data1$district): could not find function "cluster.vcov"
coeftest(model2, vcov2)
#> Error in coeftest(model2, vcov2): object 'model2' not found
model1_clustered= felm(latrine~ mboy_post +mboy +post | 0 | 0 | district, data=data1)
#> Error in ..pdata.coerce..(data1): object 'data1' not found
summary(model1_clustered)
#> Error in summary(model1_clustered): object 'model1_clustered' not found
Created on 2018-03-22 by the reprex package (v0.2.0).
I am not an expert in this area, but I know there are a number of ways to calculate robust standard errors.
To find out how this package and Stata implement their particular methods, you'll want to check out the documentation.
For the lfe package, check out the docs here: https://cran.r-project.org/web/packages/lfe/lfe.pdf
The line "The package may optionally compute standard errors for the group effects by bootstrapping, but this is a very time and memory-consuming process compared to finding the point estimates." one source of possible discrepancy between the two.
Looking at stata's documentationhttps://www.stata.com/manuals13/xtvce_options.pdf
Note the line under clustered sandwich estimator Methods and formulas; "By default, Stata’s maximum likelihood estimators display standard errors based on variance estimates given by the inverse of the negative Hessian (second derivative) matrix. If vce(robust), vce(cluster clustvar), or pweights are specified, standard errors are based on the robust variance estimator..."
The problem seems to be that one of the districts that Stata treats as missing, R is treating as valid. The district is named "", literally just a character vector of length zero. This is an issue relating to how the data were transferred from Stata format to R. Here's my code that I used to reproduce the Stata output.
dat <- haven::read_dta("master-data-clean.dta")
dat1 <- subset(dat, haryana == 1)
dat1 <- subset(dat1, district != "")
model <- lm(latrine ~ mboy_post + mboy + post, data = dat1)
library(jtools) # for `summ` function
summ(model, robust = TRUE, robust.type = "HC1", cluster = "district")
#> MODEL INFO:
#> Observations: 32915
#> Dependent Variable: latrine
#>
#> MODEL FIT:
#> F(3,32911) = 400.19, p = 0
#> R-squared = 0.04
#> Adj. R-squared = 0.04
#>
#> Standard errors: Cluster-robust, type = HC1
#> Est. S.E. t val. p
#> (Intercept) 0.28 0.02 12.28 0 ***
#> mboy_post 0.07 0.01 4.78 0 ***
#> mboy 0.01 0.01 0.97 0.33
#> post 0.15 0.04 3.9 0 ***
There's no specific need for the jtools package — I'm its developer and so used it because I know how it works and knew that it would work. The robust SEs are calculated using the sandwich package which you could do separately. You might want to use the digits argument to summ to match more decimal places with the Stata output, but it matches exactly on my computer (other than the degrees of freedom for the F test, which is very low on Stata for reasons I don't understand).
As a side note, in R it is typical to model interactions using the formula syntax (e.g., latrine ~ mboy * post rather than create a new variable that is the product of those two variables.