That's already the hardest part of f(x) = y, clearly stating the matter to be determined. Everything in R is an object, including operators, such as + - * / and all functions f.
x is what is to hand and y is what is to be derived with f.
To start, x is a set of csv files, and each is to be converted to a data frame for further treatment, selection of the three variables of interest. Bringing us to
What does the current code do, using the sample data, shown by a a reprex (see the FAQ).
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
# variable names changed to remove need for back quotes
d <- data.frame(Document = c(
"Testfile100_xmi", "Testfile101_xmi",
"Testfile101_xmi", "Testfile103_xmi", "Testfile106_xmi", "Testfile109_xmi",
"Testfile109_xmi", "Testfile10_xmi", "Testfile10_xmi", "Testfile110_xmi",
"Testfile119_xmi", "Testfile121_xmi", "Testfile122_xmi", "Testfile122_xmi",
"Testfile122_xmi", "Testfile124_xmi", "Testfile124_xmi", "Testfile125_xmi",
"Testfile128_xmi", "Testfile129_xmi", "Testfile129_xmi", "Testfile132_xmi",
"Testfile135_xmi", "Testfile139_xmi"
), Aspect = c(
"Jan Wagner",
"Gewinner des #Büchnerpreis", "er", "Scheißgedicht", "Lesung",
"Alternative Büchnerpreis", "Wondratschek", "Büchnerpreisträger",
"Büchnerpreisträger", "LITERARISCHEN WELT", "Jan Wagner", "Gedicht über den Giersch",
"Büchnerpreis-Jury zeichnet", "weiße Männer", "weiße Männer um 61",
"„Gold. Revue“", "Hörspiel", "Gold. Revue", "büchnerpreis",
"Büchnerpreisträger", "Büchnerpreisträger", "Büchnerpreis",
"Er", "Gute Wahl! #GeorgBüchnerPreis"
), Aspect_category = c(
"CONTENDER_General",
"META_Winner_Award-Ceremony", "CONTENDER_General", "TEXT_General",
"READING_General", "META_Literature_Literary-Prizes", "ALLO-REFERENCES_TEXT_Other-Author",
"META_Winner_Award-Ceremony", "CONTENDER_General", "META_Literature_Literary-Prizes",
"CONTENDER_General", "TEXT_General-Content_Plot", "JURY_Discussion_Valuation",
"CONTENDER_Gender", "CONTENDER_Age", "TEXT_General", "TEXT_Form",
"TEXT_General", "META_Main-Event", "CONTENDER_General", "META_Winner_Award-Ceremony",
"META_Main-Event", "CONTENDER_General", "META_Winner_Award-Ceremony"
), Polarity_Trigger = c(
"Sprachkünstler", "Gratulation!", "Gratulation!",
"Scheißgedicht", "konzertanten", "klotzen!", "Alternative Büchnerpreis sollte jedes Jahr an Wondratschek gehen",
"ganz besonderen", "ganz besonderen", "geht auch nur in der LITERARISCHEN WELT",
"the Billy Collins of contemporary German poetry", "sensationelles",
"zeichnet im Schnitt weiße Männer um 61 aus, die bei den vier großen Verlagen erscheinen",
"weiße Männer um 61 ", "weiße Männer um 61 ", "des Monats",
"des Monats", "des Monats", "Gänsehaut pur!,großes", "herausragender",
"herausragender", "Tatenvolumen!", "meisterhaft", "Gute Wahl!"
), Span_lore = c(
"[(31, 45)]", "[(129, 141)]", "[(129, 141)]",
"[(19, 32)]", "[(99, 111)]", "[(18, 26)]", "[(31, 95)]", "[(12, 27)]",
"[(12, 27)]", "[(81, 120)]", "[(61, 108)]", "[(14, 28)]", "[(24, 111)]",
"[(24, 111)]", "[(24, 111)]", "[(81, 91)]", "[(81, 91)]", "[(12, 22)]",
"[(28, 34), (2, 16)]", "[(55, 69)]", "[(55, 69)]", "[(2, 15)]",
"[(18, 29)]", "[(2, 12)]"
), Polarity_lore = c(
"Positive", "Positive",
"Positive", "Negative", "Positive", "Positive", "Positive", "Positive",
"Positive", "Negative", "Positive", "Positive", "Negative", "Negative",
"Negative", "Positive", "Positive", "Positive", "Positive", "Positive",
"Positive", "Positive", "Positive", "Positive"
), Irony_lore = c(
"false",
"false", "false", "true", "false", "false", "false", "false",
"false", "false", "false", "false", "false", "false", "false",
"false", "false", "false", "false", "false", "false", "false",
"false", "true"
))
# Filter relevant columns: Aspect_category, Polarity_lore, and Irony_lore
df_filtered <- d |>
select(Aspect_category, Polarity_lore, Irony_lore)
# Calculate the counts for each category, sentiment, and irony combination
counts <- df_filtered |>
group_by(Aspect_category, Polarity_lore, Irony_lore) |>
summarise(count = n()) |>
ungroup()
#> `summarise()` has grouped output by 'Aspect_category', 'Polarity_lore'. You can
#> override using the `.groups` argument.
counts
#> # A tibble: 15 × 4
#> Aspect_category Polarity_lore Irony_lore count
#> <chr> <chr> <chr> <int>
#> 1 ALLO-REFERENCES_TEXT_Other-Author Positive false 1
#> 2 CONTENDER_Age Negative false 1
#> 3 CONTENDER_Gender Negative false 1
#> 4 CONTENDER_General Positive false 6
#> 5 JURY_Discussion_Valuation Negative false 1
#> 6 META_Literature_Literary-Prizes Negative false 1
#> 7 META_Literature_Literary-Prizes Positive false 1
#> 8 META_Main-Event Positive false 2
#> 9 META_Winner_Award-Ceremony Positive false 3
#> 10 META_Winner_Award-Ceremony Positive true 1
#> 11 READING_General Positive false 1
#> 12 TEXT_Form Positive false 1
#> 13 TEXT_General Negative true 1
#> 14 TEXT_General Positive false 2
#> 15 TEXT_General-Content_Plot Positive false 1
Created on 2023-05-21 with reprex v2.0.2
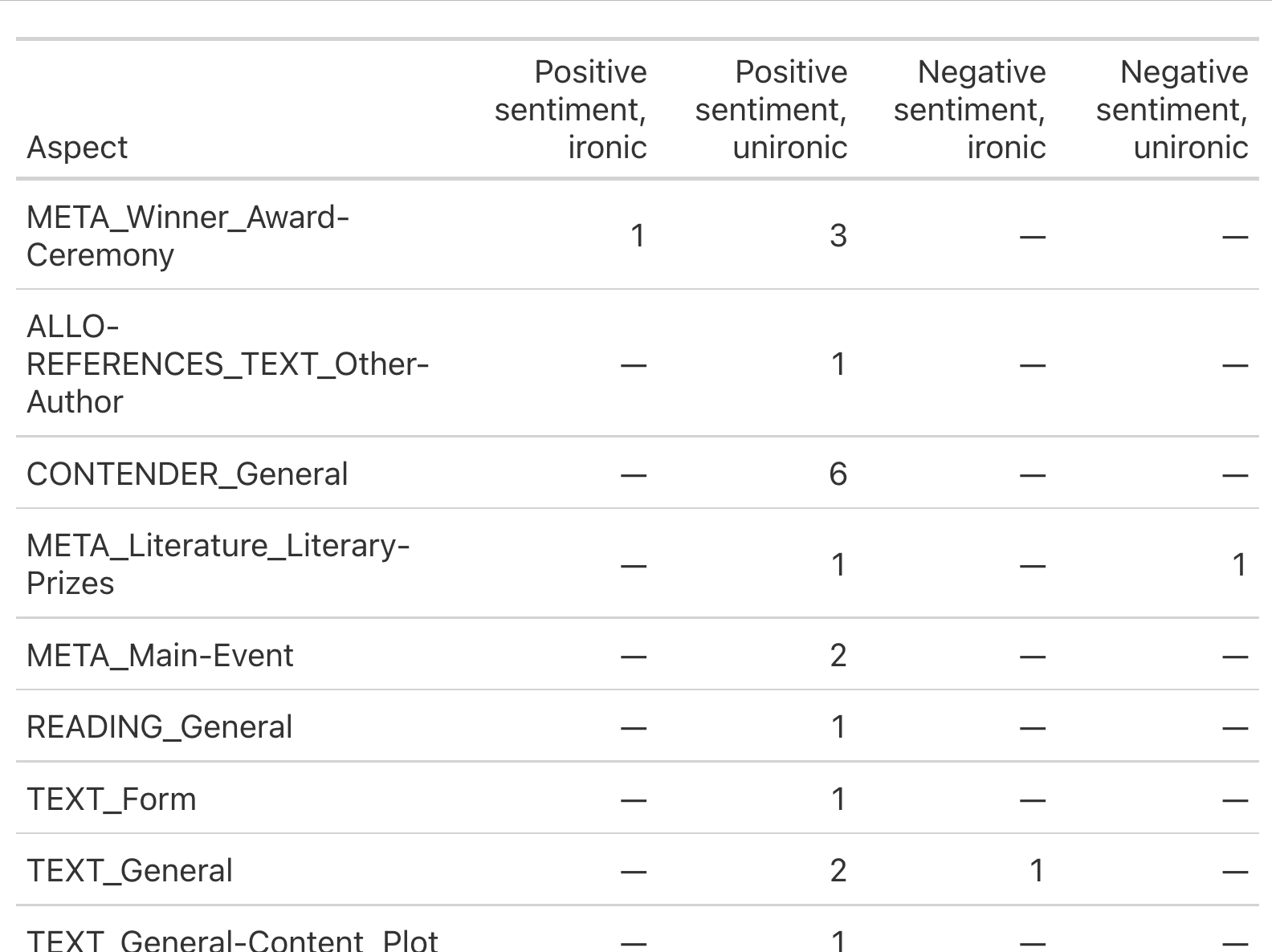
The result is arguably what we were looking for, but the arrangement isn't very useful, especially since several of these are going to be pasted together. When this happens, it usually help to design y first, and then work backwards. To begin let's look at the sample space—what is the set of possible outcomes?
There are four possibilities for each aspect with respect to sentiment and irony
- POSITIVE_TRUE
- POSITIVE_FALSE
- NEGATIVE_TRUE
- NEGATIVE_FALSE
To produce this table
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(gt)
library(janitor)
#>
#> Attaching package: 'janitor'
#> The following objects are masked from 'package:stats':
#>
#> chisq.test, fisher.test
d <- data.frame(Document = c(
"Testfile100_xmi", "Testfile101_xmi",
"Testfile101_xmi", "Testfile103_xmi", "Testfile106_xmi", "Testfile109_xmi",
"Testfile109_xmi", "Testfile10_xmi", "Testfile10_xmi", "Testfile110_xmi",
"Testfile119_xmi", "Testfile121_xmi", "Testfile122_xmi", "Testfile122_xmi",
"Testfile122_xmi", "Testfile124_xmi", "Testfile124_xmi", "Testfile125_xmi",
"Testfile128_xmi", "Testfile129_xmi", "Testfile129_xmi", "Testfile132_xmi",
"Testfile135_xmi", "Testfile139_xmi"
), Aspect = c(
"Jan Wagner",
"Gewinner des #Büchnerpreis", "er", "Scheißgedicht", "Lesung",
"Alternative Büchnerpreis", "Wondratschek", "Büchnerpreisträger",
"Büchnerpreisträger", "LITERARISCHEN WELT", "Jan Wagner", "Gedicht über den Giersch",
"Büchnerpreis-Jury zeichnet", "weiße Männer", "weiße Männer um 61",
"„Gold. Revue“", "Hörspiel", "Gold. Revue", "büchnerpreis",
"Büchnerpreisträger", "Büchnerpreisträger", "Büchnerpreis",
"Er", "Gute Wahl! #GeorgBüchnerPreis"
), Aspect_category = c(
"CONTENDER_General",
"META_Winner_Award-Ceremony", "CONTENDER_General", "TEXT_General",
"READING_General", "META_Literature_Literary-Prizes", "ALLO-REFERENCES_TEXT_Other-Author",
"META_Winner_Award-Ceremony", "CONTENDER_General", "META_Literature_Literary-Prizes",
"CONTENDER_General", "TEXT_General-Content_Plot", "JURY_Discussion_Valuation",
"CONTENDER_Gender", "CONTENDER_Age", "TEXT_General", "TEXT_Form",
"TEXT_General", "META_Main-Event", "CONTENDER_General", "META_Winner_Award-Ceremony",
"META_Main-Event", "CONTENDER_General", "META_Winner_Award-Ceremony"
), Polarity_Trigger = c(
"Sprachkünstler", "Gratulation!", "Gratulation!",
"Scheißgedicht", "konzertanten", "klotzen!", "Alternative Büchnerpreis sollte jedes Jahr an Wondratschek gehen",
"ganz besonderen", "ganz besonderen", "geht auch nur in der LITERARISCHEN WELT",
"the Billy Collins of contemporary German poetry", "sensationelles",
"zeichnet im Schnitt weiße Männer um 61 aus, die bei den vier großen Verlagen erscheinen",
"weiße Männer um 61 ", "weiße Männer um 61 ", "des Monats",
"des Monats", "des Monats", "Gänsehaut pur!,großes", "herausragender",
"herausragender", "Tatenvolumen!", "meisterhaft", "Gute Wahl!"
), Span_lore = c(
"[(31, 45)]", "[(129, 141)]", "[(129, 141)]",
"[(19, 32)]", "[(99, 111)]", "[(18, 26)]", "[(31, 95)]", "[(12, 27)]",
"[(12, 27)]", "[(81, 120)]", "[(61, 108)]", "[(14, 28)]", "[(24, 111)]",
"[(24, 111)]", "[(24, 111)]", "[(81, 91)]", "[(81, 91)]", "[(12, 22)]",
"[(28, 34), (2, 16)]", "[(55, 69)]", "[(55, 69)]", "[(2, 15)]",
"[(18, 29)]", "[(2, 12)]"
), Polarity_lore = c(
"Positive", "Positive",
"Positive", "Negative", "Positive", "Positive", "Positive", "Positive",
"Positive", "Negative", "Positive", "Positive", "Negative", "Negative",
"Negative", "Positive", "Positive", "Positive", "Positive", "Positive",
"Positive", "Positive", "Positive", "Positive"
), Irony_lore = c(
"false",
"false", "false", "true", "false", "false", "false", "false",
"false", "false", "false", "false", "false", "false", "false",
"false", "false", "false", "false", "false", "false", "false",
"false", "true"
))
# Filter relevant columns: Aspect_category, Polarity_lore, and Irony_lore
df_filtered <- d |>
select(Aspect_category, Polarity_lore, Irony_lore)
df_filtered$Polarity_lore <- ifelse(df_filtered$Polarity_lore == "Positive",TRUE,FALSE)
df_filtered$Irony_lore <- ifelse(df_filtered$Irony_lore == "true",TRUE,FALSE)
case1 <- df_filtered[which(df_filtered$Polarity_lore == TRUE &
df_filtered$Irony_lore == TRUE),]
case2 <- df_filtered[which(df_filtered$Polarity_lore == TRUE &
df_filtered$Irony_lore == FALSE),]
case3 <- df_filtered[which(df_filtered$Polarity_lore == FALSE &
df_filtered$Irony_lore == TRUE),]
case4 <- df_filtered[which(df_filtered$Polarity_lore == FALSE &
df_filtered$Irony_lore == FALSE),]
case1 <- as.data.frame(tabyl(case1,Aspect_category,Polarity_lore,Irony_lore))
colnames(case1) <- c("Aspect_category", "case1")
case2 <- as.data.frame(tabyl(case2,Aspect_category,Polarity_lore,Irony_lore))
colnames(case2) <- c("Aspect_category", "case2")
case3 <- as.data.frame(tabyl(case3,Aspect_category,Polarity_lore,Irony_lore))
colnames(case3) <- c("Aspect_category","case3")
case4 <- as.data.frame(tabyl(case4,Aspect_category,Polarity_lore,Irony_lore))
colnames(case4) <- c("Aspect_category","case4")
cases <- full_join(case1,case2,by = "Aspect_category")
cases <- full_join(cases,case3,by = "Aspect_category")
cases <- full_join(cases,case4,by = "Aspect_category")
# presentation table
cases |>
gt() |>
cols_label(
Aspect_category = "Aspect",
case1 = "Positive sentiment, ironic",
case2 = "Positive sentiment, unironic",
case3 = "Negative sentiment, ironic",
case4 = "Negative sentiment, unironic"
) |>
sub_missing()