Hello everyone,
I have a bunch of csv-files (one per corpus) containing annotated data in multiple columns. I wish to look at the results of an aspect based sentiment analysis. Unfortunately it's a lot of different files and outputs to calculate manually. It would be very helpful if I could use a script to automatically do the calculations instead of using the filter.
The first type of document simply contains the annotated aspects: the name of the annotated file ("Document"), the annotated target wordgroup ("Aspect"), and the aspect category ("lore"). Here I would like to know how many of each category there are.
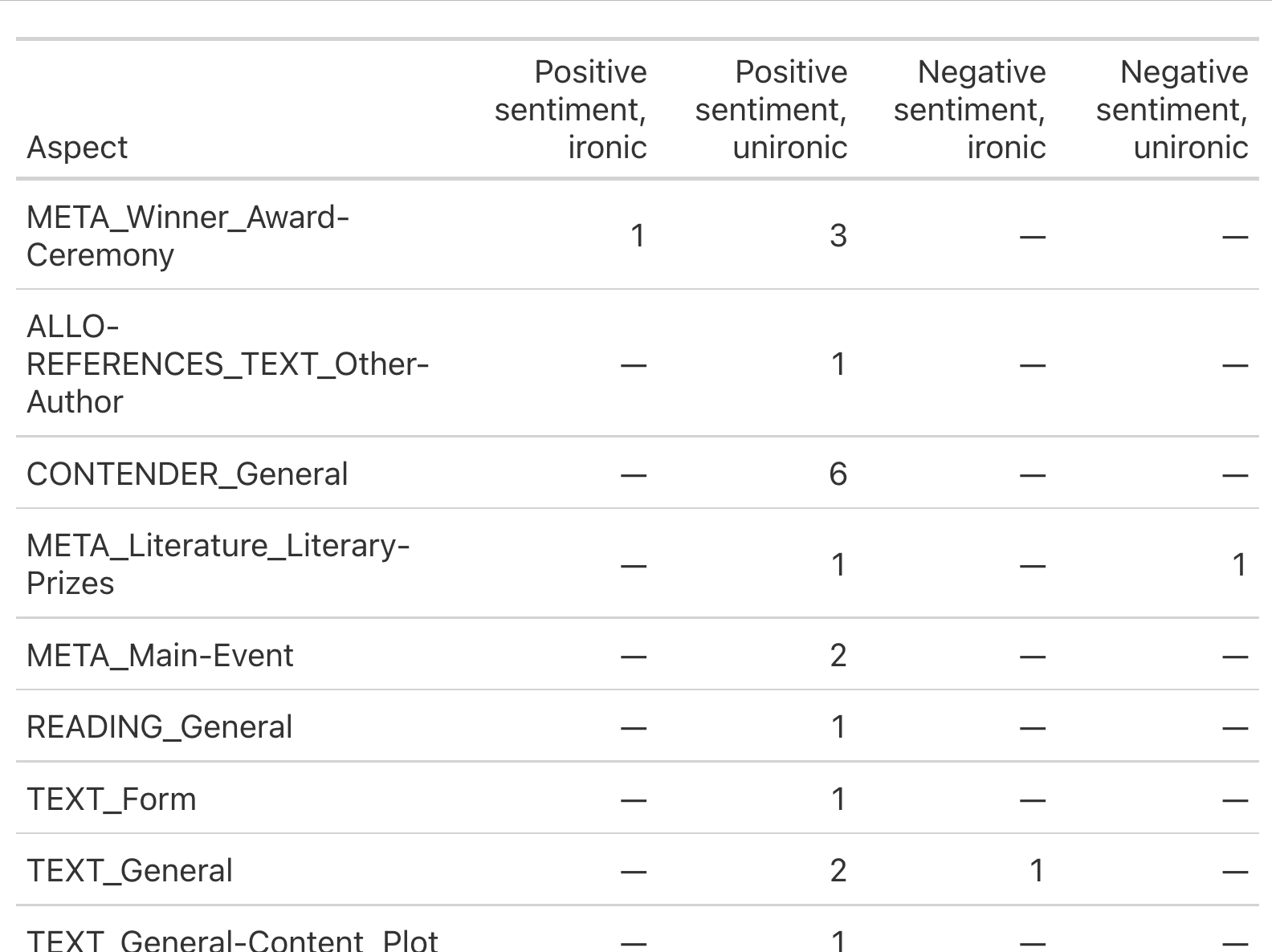
The second type of document contains my annotated data combining aspect and seniment. The only relevant columns are "Aspect category", "Polarity lore" and "Irony lore". The first column contains the category labels which have been assigned to the aspects, such as "Text". The second column assigns a sentiment label to the aspect, namely "Positive" or "Negative" (sometimes there is failed label). The last column tells you wether the sentiment is meant ironically ("true" or "false"). I wish to know how often each aspect category is mentioned in combination with either positive or negative sentiment and how many of these positive or negative sentiments were meant ironically.
Thirdly, I have files containing automatically annotated data, with several columns. The only relevant ones are a column for the aspect category ("Category_Fine") and for the pertaining sentiment ("Polarity").
I wanted to try my hand at the second one first since it seemed the most complicated one. My coding knowledge, however, is very limited. My colleague recommended creating a script via chatGPT . No true surprizes there, but it did not work. Of course, it couldn't hurt to try. I would be very grateful if anyone would be willing and have the time to help.
I will included the failing script below, as it might be of some help? I also have an example csv-file containing only some 25 lines to test it on, but am not sure how I can include it here, so I'll just add the lines at the end, I guess?
library(tidyverse)
# Set the path to your CSV files directory
csv_directory <- "path/to/csv/files"
# Get a list of all CSV files in the directory
csv_files <- list.files(csv_directory, pattern = "\\.csv$", full.names = TRUE)
# Initialize an empty data frame to store the results
results <- data.frame(Category = character(), Positive = integer(), Negative = integer(), Irony_True = integer(), Irony_False = integer(), stringsAsFactors = FALSE)
# Loop through each CSV file
for (csv_file in csv_files) {
# Read the CSV file into a data frame
df <- read_csv(csv_file)
# Filter relevant columns: Aspect category, Polarity lore, and Irony lore
df_filtered <- df %>%
select(`Aspect category`, `Polarity lore`, `Irony lore`)
# Calculate the counts for each category, sentiment, and irony combination
counts <- df_filtered %>%
group_by(`Aspect category`, `Polarity lore`, `Irony lore`) %>%
summarise(count = n()) %>%
ungroup()
# Add the counts to the results data frame
results <- bind_rows(results, counts)
}
# Write the results to a new CSV file
write_csv(results, "output_file.csv")
Thank you in advance for your time, patience and help!
The example data (tab delimiter):
Document Aspect Aspect category Polarity Trigger Span lore Polarity lore Irony lore
Testfile100_xmi Jan Wagner CONTENDER_General Sprachkünstler [(31, 45)] Positive false
Testfile101_xmi Gewinner des #Büchnerpreis META_Winner_Award-Ceremony Gratulation! [(129, 141)] Positive false
Testfile101_xmi er CONTENDER_General Gratulation! [(129, 141)] Positive false
Testfile103_xmi Scheißgedicht TEXT_General Scheißgedicht [(19, 32)] Negative true
Testfile106_xmi Lesung READING_General konzertanten [(99, 111)] Positive false
Testfile109_xmi Alternative Büchnerpreis META_Literature_Literary-Prizes klotzen! [(18, 26)] Positive false
Testfile109_xmi Wondratschek ALLO-REFERENCES_TEXT_Other-Author Alternative Büchnerpreis sollte jedes Jahr an Wondratschek gehen [(31, 95)] Positive false
Testfile10_xmi Büchnerpreisträger META_Winner_Award-Ceremony ganz besonderen [(12, 27)] Positive false
Testfile10_xmi Büchnerpreisträger CONTENDER_General ganz besonderen [(12, 27)] Positive false
Testfile110_xmi LITERARISCHEN WELT META_Literature_Literary-Prizes geht auch nur in der LITERARISCHEN WELT [(81, 120)] Negative false
Testfile119_xmi Jan Wagner CONTENDER_General the Billy Collins of contemporary German poetry [(61, 108)] Positive false
Testfile121_xmi Gedicht über den Giersch TEXT_General-Content_Plot sensationelles [(14, 28)] Positive false
Testfile122_xmi Büchnerpreis-Jury zeichnet JURY_Discussion_Valuation zeichnet im Schnitt weiße Männer um 61 aus, die bei den vier großen Verlagen erscheinen [(24, 111)] Negative false
Testfile122_xmi weiße Männer CONTENDER_Gender weiße Männer um 61 [(24, 111)] Negative false
Testfile122_xmi weiße Männer um 61 CONTENDER_Age weiße Männer um 61 [(24, 111)] Negative false
Testfile124_xmi „Gold. Revue“ TEXT_General des Monats [(81, 91)] Positive false
Testfile124_xmi Hörspiel TEXT_Form des Monats [(81, 91)] Positive false
Testfile125_xmi Gold. Revue TEXT_General des Monats [(12, 22)] Positive false
Testfile128_xmi büchnerpreis META_Main-Event Gänsehaut pur!,großes [(28, 34), (2, 16)] Positive false
Testfile129_xmi Büchnerpreisträger CONTENDER_General herausragender [(55, 69)] Positive false
Testfile129_xmi Büchnerpreisträger META_Winner_Award-Ceremony herausragender [(55, 69)] Positive false
Testfile132_xmi Büchnerpreis META_Main-Event Tatenvolumen! [(2, 15)] Positive false
Testfile135_xmi Er CONTENDER_General meisterhaft [(18, 29)] Positive false
Testfile139_xmi Gute Wahl! #GeorgBüchnerPreis META_Winner_Award-Ceremony Gute Wahl! [(2, 12)] Positive true