I am having a problem merging two datasets. Each is extracting data from the same file.
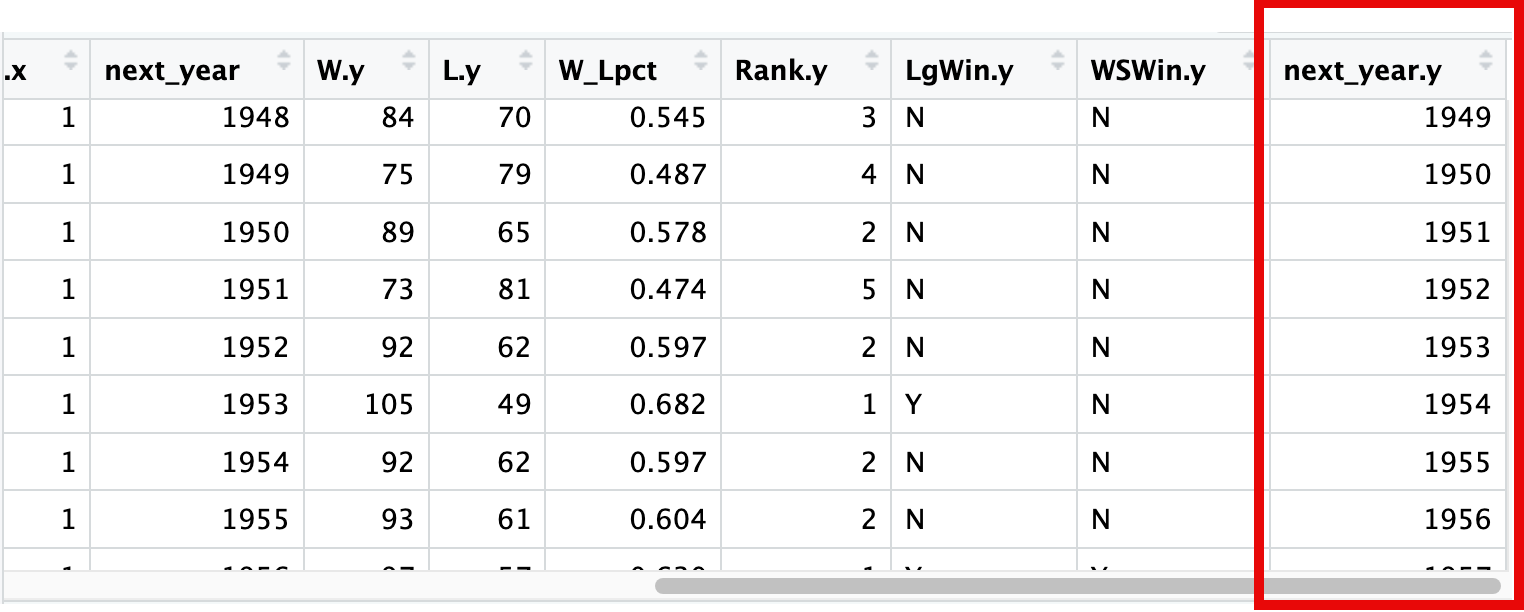
Here is the output from the first part of the code. It is for one season.
Here is the code:
library("Lahman")
WS_Losers <- Teams %>%
filter(yearID >= 1901 & lgID %in% c("AL","NL")) |>
filter(LgWin == "Y" & WSWin == "N") %>%
mutate(next_year = yearID + 1) %>%
select(yearID, teamID, LgWin, WSWin, W, L, Rank, next_year)
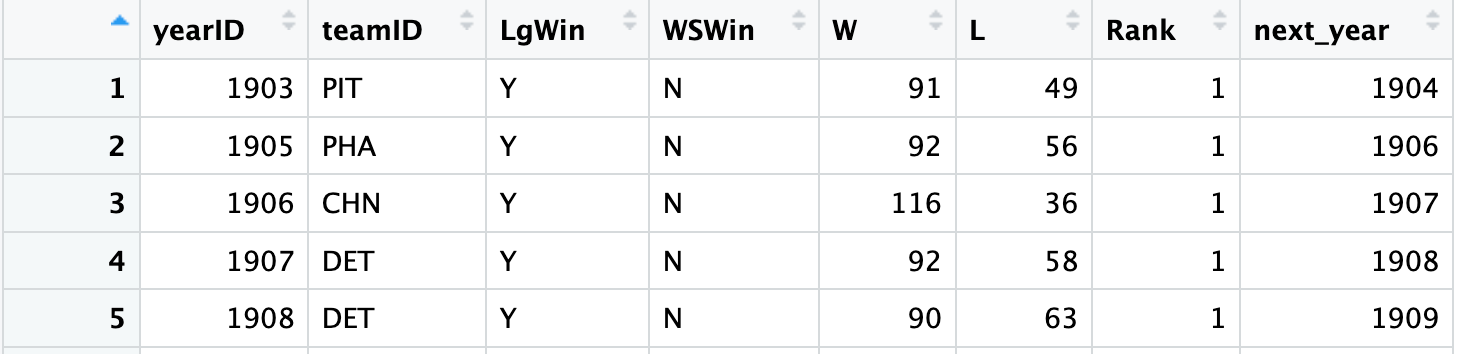
Here is the output from the second part of the code. The data I am interested in is for the same team but one season later.
Here is my code:
Won_Lost_Next <- Teams %>%
filter(yearID >= 1901 & lgID %in% c("AL", "NL")) %>%
mutate(W_Lpct = round(W / (W + L), 3)) %>%
select(yearID, teamID, W, L, W_Lpct, Rank, LgWin, WSWin, next_year)
Here is the rest of the code to merge the two datasets:
merged_df <- inner_join(WS_Losers, Won_Lost_Next, by = c("next_year" = "yearID", "teamID"))
write.csv(merged_df, "merged_file.csv", row.names = FALSE)
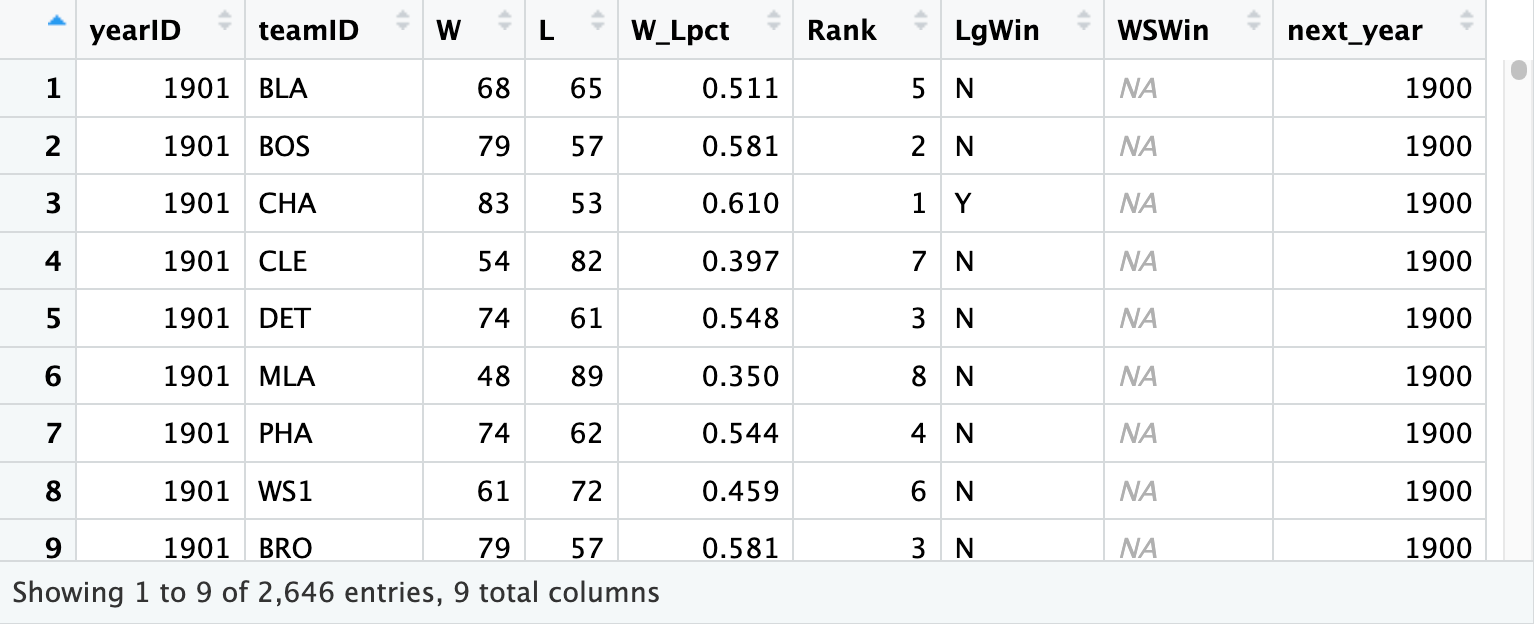
Here are the output of each dataset.
dput(head(WS_Losers, 10))
structure(list(yearID = c(1903L, 1905L, 1906L, 1907L, 1908L,
1909L, 1910L, 1911L, 1912L, 1913L), teamID = structure(c(106L,
101L, 35L, 52L, 52L, 52L, 35L, 89L, 89L, 89L), levels = c("ALT",
"ANA", "ARI", "ATL", "BAL", "BFN", "BFP", "BL1", "BL2", "BL3",
"BL4", "BLA", "BLF", "BLN", "BLU", "BOS", "BR1", "BR2", "BR3",
"BR4", "BRF", "BRO", "BRP", "BS1", "BS2", "BSN", "BSP", "BSU",
"BUF", "CAL", "CH1", "CH2", "CHA", "CHF", "CHN", "CHP", "CHU",
"CIN", "CL1", "CL2", "CL3", "CL4", "CL5", "CL6", "CLE", "CLP",
"CN1", "CN2", "CN3", "CNU", "COL", "DET", "DTN", "ELI", "FLO",
"FW1", "HAR", "HOU", "HR1", "IN1", "IN2", "IN3", "IND", "KC1",
"KC2", "KCA", "KCF", "KCN", "KCU", "KEO", "LAA", "LAN", "LS1",
"LS2", "LS3", "MIA", "MID", "MIL", "MIN", "ML1", "ML2", "ML3",
"ML4", "MLA", "MLU", "MON", "NEW", "NH1", "NY1", "NY2", "NY3",
"NY4", "NYA", "NYN", "NYP", "OAK", "PH1", "PH2", "PH3", "PH4",
"PHA", "PHI", "PHN", "PHP", "PHU", "PIT", "PRO", "PT1", "PTF",
"PTP", "RC1", "RC2", "RIC", "SDN", "SE1", "SEA", "SFN", "SL1",
"SL2", "SL3", "SL4", "SL5", "SLA", "SLF", "SLN", "SLU", "SPU",
"SR1", "SR2", "TBA", "TEX", "TL1", "TL2", "TOR", "TRN", "TRO",
"WAS", "WIL", "WOR", "WS1", "WS2", "WS3", "WS4", "WS5", "WS6",
"WS7", "WS8", "WS9", "WSU"), class = "factor"), LgWin = c("Y",
"Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y"), WSWin = c("N",
"N", "N", "N", "N", "N", "N", "N", "N", "N"), W = c(91L, 92L,
116L, 92L, 90L, 98L, 104L, 99L, 103L, 101L), L = c(49L, 56L,
36L, 58L, 63L, 54L, 50L, 54L, 48L, 51L), Rank = c(1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L), next_year = c(1904, 1906, 1907,
1908, 1909, 1910, 1911, 1912, 1913, 1914)), row.names = c(NA,
10L), class = "data.frame")
dput(head(Won_Lost_Next, 40))
structure(list(yearID = c(1901L, 1901L, 1901L, 1901L, 1901L,
1901L, 1901L, 1901L, 1901L, 1901L, 1901L, 1901L, 1901L, 1901L,
1901L, 1901L, 1902L, 1902L, 1902L, 1902L, 1902L, 1902L, 1902L,
1902L, 1902L, 1902L, 1902L, 1902L, 1902L, 1902L, 1902L, 1902L,
1903L, 1903L, 1903L, 1903L, 1903L, 1903L, 1903L, 1903L), teamID = structure(c(12L,
16L, 33L, 45L, 52L, 84L, 101L, 140L, 22L, 26L, 35L, 38L, 89L,
102L, 106L, 125L, 12L, 16L, 33L, 45L, 52L, 101L, 123L, 140L,
22L, 26L, 35L, 38L, 89L, 102L, 106L, 125L, 16L, 33L, 45L, 52L,
93L, 101L, 123L, 140L), levels = c("ALT", "ANA", "ARI", "ATL",
"BAL", "BFN", "BFP", "BL1", "BL2", "BL3", "BL4", "BLA", "BLF",
"BLN", "BLU", "BOS", "BR1", "BR2", "BR3", "BR4", "BRF", "BRO",
"BRP", "BS1", "BS2", "BSN", "BSP", "BSU", "BUF", "CAL", "CH1",
"CH2", "CHA", "CHF", "CHN", "CHP", "CHU", "CIN", "CL1", "CL2",
"CL3", "CL4", "CL5", "CL6", "CLE", "CLP", "CN1", "CN2", "CN3",
"CNU", "COL", "DET", "DTN", "ELI", "FLO", "FW1", "HAR", "HOU",
"HR1", "IN1", "IN2", "IN3", "IND", "KC1", "KC2", "KCA", "KCF",
"KCN", "KCU", "KEO", "LAA", "LAN", "LS1", "LS2", "LS3", "MIA",
"MID", "MIL", "MIN", "ML1", "ML2", "ML3", "ML4", "MLA", "MLU",
"MON", "NEW", "NH1", "NY1", "NY2", "NY3", "NY4", "NYA", "NYN",
"NYP", "OAK", "PH1", "PH2", "PH3", "PH4", "PHA", "PHI", "PHN",
"PHP", "PHU", "PIT", "PRO", "PT1", "PTF", "PTP", "RC1", "RC2",
"RIC", "SDN", "SE1", "SEA", "SFN", "SL1", "SL2", "SL3", "SL4",
"SL5", "SLA", "SLF", "SLN", "SLU", "SPU", "SR1", "SR2", "TBA",
"TEX", "TL1", "TL2", "TOR", "TRN", "TRO", "WAS", "WIL", "WOR",
"WS1", "WS2", "WS3", "WS4", "WS5", "WS6", "WS7", "WS8", "WS9",
"WSU"), class = "factor"), W = c(68L, 79L, 83L, 54L, 74L, 48L,
74L, 61L, 79L, 69L, 53L, 52L, 52L, 83L, 90L, 76L, 50L, 77L, 74L,
69L, 52L, 83L, 78L, 61L, 75L, 73L, 68L, 70L, 48L, 56L, 103L,
56L, 91L, 60L, 77L, 65L, 72L, 75L, 65L, 43L), L = c(65L, 57L,
53L, 82L, 61L, 89L, 62L, 72L, 57L, 69L, 86L, 87L, 85L, 57L, 49L,
64L, 88L, 60L, 60L, 67L, 83L, 53L, 58L, 75L, 63L, 64L, 69L, 70L,
88L, 81L, 36L, 78L, 47L, 77L, 63L, 71L, 62L, 60L, 74L, 94L),
W_Lpct = c(0.511, 0.581, 0.61, 0.397, 0.548, 0.35, 0.544,
0.459, 0.581, 0.5, 0.381, 0.374, 0.38, 0.593, 0.647, 0.543,
0.362, 0.562, 0.552, 0.507, 0.385, 0.61, 0.574, 0.449, 0.543,
0.533, 0.496, 0.5, 0.353, 0.409, 0.741, 0.418, 0.659, 0.438,
0.55, 0.478, 0.537, 0.556, 0.468, 0.314), Rank = c(5L, 2L,
1L, 7L, 3L, 8L, 4L, 6L, 3L, 5L, 6L, 8L, 7L, 2L, 1L, 4L, 8L,
3L, 4L, 5L, 7L, 1L, 2L, 6L, 2L, 3L, 5L, 4L, 8L, 7L, 1L, 6L,
1L, 7L, 3L, 5L, 4L, 2L, 6L, 8L), LgWin = c("N", "N", "Y",
"N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "Y",
"N", "N", "N", "N", "N", "N", "Y", "N", "N", "N", "N", "N",
"N", "N", "N", "Y", "N", "Y", "N", "N", "N", "N", "N", "N",
"N"), WSWin = c(NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, "Y", "N", "N", "N", "N", "N", "N",
"N"), next_year = c(1902, 1902, 1902, 1902, 1902, 1902, 1902,
1902, 1902, 1902, 1902, 1902, 1902, 1902, 1902, 1902, 1903,
1903, 1903, 1903, 1903, 1903, 1903, 1903, 1903, 1903, 1903,
1903, 1903, 1903, 1903, 1903, 1904, 1904, 1904, 1904, 1904,
1904, 1904, 1904)), row.names = c(NA, 40L), class = "data.frame")
What I want to do is to merge what is in the second image with what is in the first image with the corresponding rows aligning. One problem is that in the second image, the next_year column should be one year higher than the yearID,as it is in the first image. Further, the data that is added should be the data for the same team but one year later, so for the 1901 Boston team, the data should be that for the same team but in the 1902 season. I am comparing how a team that played in the World Series in one season performed during the following season.
I would appreciate help in getting this code to produce the desired result.
Howard