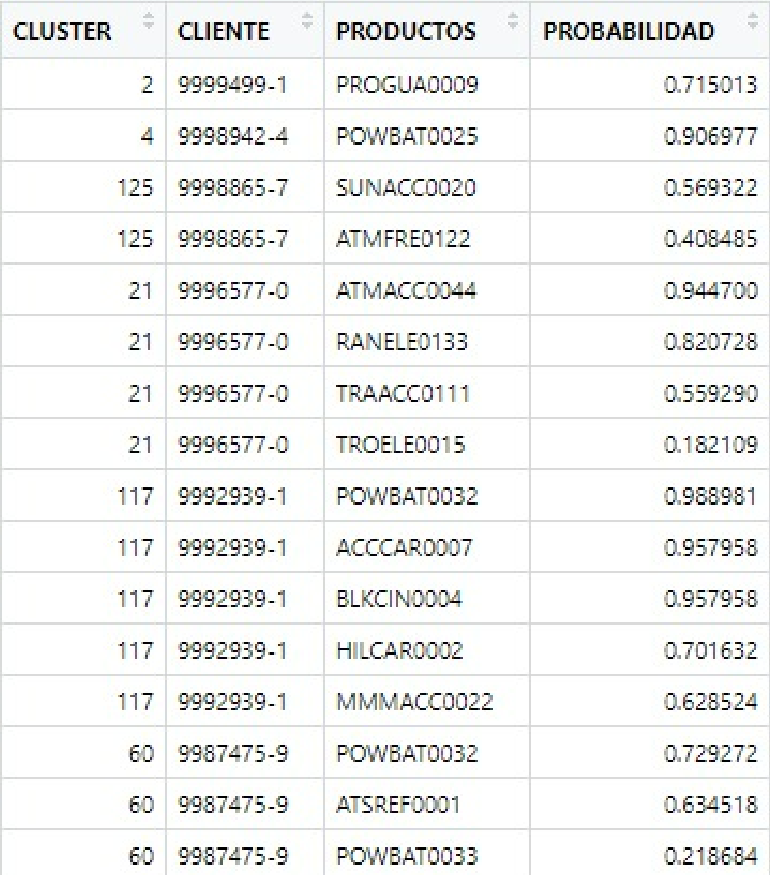
Hello,
About this:
df <- data.frame(client = c("1a", "1a", "2b", "2b", "3c", "3c", "4d", "4c", "4c"),
sku = c(1, 2, 3, 4, 3, 2, 1, 1, 2),
frequency = c(4,3,2,1,2,2,4,5,5))
How can I obtain the probability of buy? like:
client sku frequency prob
1 1a 1 4 x
2 1a 2 3 x
3 2b 3 2 x
4 2b 4 1 x
5 3c 3 2 x
6 3c 2 2 x
7 4d 1 4 x
8 4c 1 5 x
9 4c 2 5 x
I tried with this link
But I can´t find a professional answer that can help me to order the maximum to the minimum probability of buy and give an appropiate recommendation, in this case is through frecuency, but I don´t know if must have more variables the df
Thanks!
For example, I think that I must count a variable or use a similar function as count().... something like this:
df %>% count() %>% mutate(prob = n/sum(n))
or do a prediction vector and add a mutate() to the df and arrange like...
arrange(desc(prediction))
I still can not obtain a solution.
I hope you can help me, thank you!
or any link!