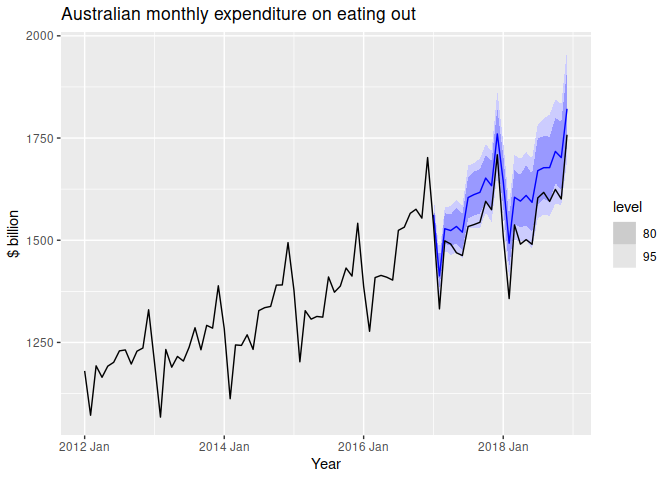
In section 13.4 Forecast combinations of the FPP3 textbook, an example demonstrates how to take the simple average of four models. (I have modified the code below to predict only 2 years worth of values so it can run faster.)
From what I can tell, cafe_fc does not automatically contain prediction interval values for the simple average method (it only contains the point predictions).
On the final step, is there an easy way to plot the prediction intervals only for the 'combination' (simple average) method?
It seems doable by manipulating cafe_fc %>% hilo() a bit, but I'm not really familiar with how to manipulate these kinds of objects (they're in a format like [1458.816, 1611.358]95).
Perhaps more importantly, would such a prediction interval be relatively accurate?
auscafe <- aus_retail %>%
filter(stringr::str_detect(Industry,"Takeaway")) %>%
summarise(Turnover = sum(Turnover))
train <- auscafe %>%
filter(year(Month) <= 2016)
STLF <- decomposition_model(
STL(log(Turnover) ~ season(window = Inf)),
ETS(season_adjust ~ season("N"))
)
cafe_models <- train %>%
model(
ets = ETS(Turnover),
stlf = STLF,
arima = ARIMA(log(Turnover)),
nnar = NNETAR(log(Turnover))
) %>%
mutate(combination = (ets + stlf + arima + nnar)/4)
cafe_fc <- cafe_models %>%
forecast(h = "2 years")
cafe_fc %>%
autoplot(auscafe %>% filter(year(Month) > 2008), level=NULL) +
xlab("Year") + ylab("$ billion") +
ggtitle("Australian monthly expenditure on eating out")