(Open ended, more discussion based question)
I've tried to tackle this problem from several angles and none are entirely 'great'.
We have an app and many people download and install it each day. We call this a cohort and the cumulative revenue from a cohort follows a growth curve that looks somewhat logarithmic in shape (but not completely). E.g.
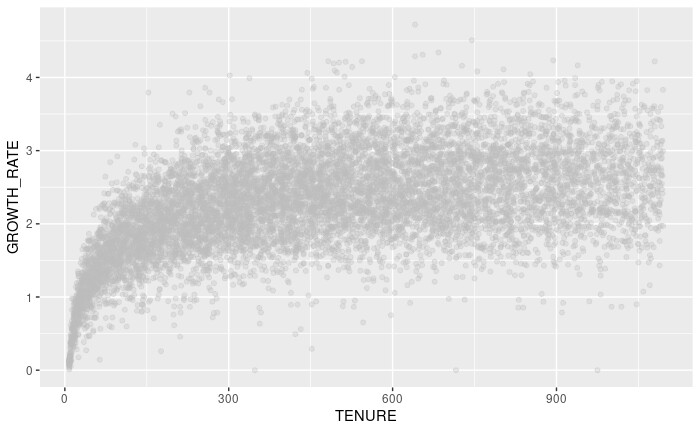
X axis is days since the cohort installed the app, y axis is the log of growth rate, e.g. log(CUMULATIVE_AMOUNT) - log(CUMULATIVE_AMOUNT_AT_DAY 7)
I tried a regression model of the form GROWTH_RATE ~ log(TENURE) and this actually did OK when testing on out of sample new data. 'OK' is subjective here. The problem is/was that, as you can see in the chart, variance widens with tenure and when plotting with plot(my.mod) residuals Vs. fitted were megaphone shaped - hetroskedasticity.
We want to be able to observe each cohort for 7 days, specifically their total spend in this first week and then use that to predict out to day 365.
Using the model above, we'd take the observed amount after day 7 and multiply by the log growth rate predicted by the model (After necessary exp() transformations).
I did some research due to the hetroskedasticity and attempted a box-cox transformation but this didn't help much.
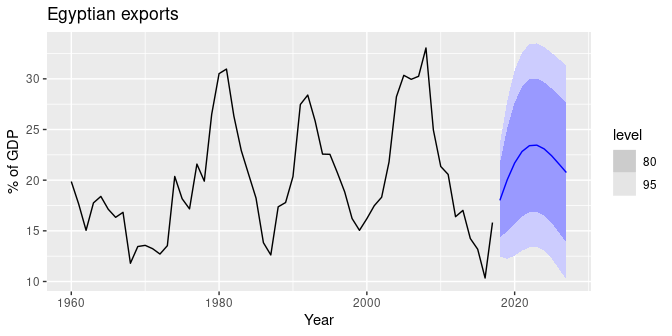
Then, the 'hint' I got from my research was that I should be using a time series model. I did some self study using Forecasting Principles and Practice book and got as far as ARIMA modeling. But, remembering that we want to observe to day 7 for each cohort before predicting out to year 1, time series approach, as far as I can see, does not facilitate this. Instead you train a model on historic data and then just predict h time periods ahead. E.g. from the book, a typical prediction block might look like this:
fit %>% forecast(h=10) %>%
autoplot(global_economy) +
labs(y = "% of GDP", title = "Egyptian exports")
Producing in this case (via linked page in book above):
For my case, I both want to fit a model based on historical data AND use the benefit of watching the first 7 days of spend data to inform any prediction.
I'm not sure what other info to provide, appreciate this is more discussion based.
What would be a 'good' approach to this problem? We have years worth of historic data to train a model on but we also want to be able to use the first 7 days of revenue to inform our predictions. Linear model with log tenure suffers from hetroskedasticity and as far as I can see time series would not make use of the first 7 days of revenue to inform the prediction.
