Below is the link for a dataset on focus. I want to split the dataset into training and test set, use training set to build the model and model tune, use test set to evaluate performance. But before doing that I want to make sure that original dataset doesn't have noise, collinearity to address, no major outliers so that I have to transform the data using techniques like Box-Cox and looking at VIF to eliminate highly correlated predictors.
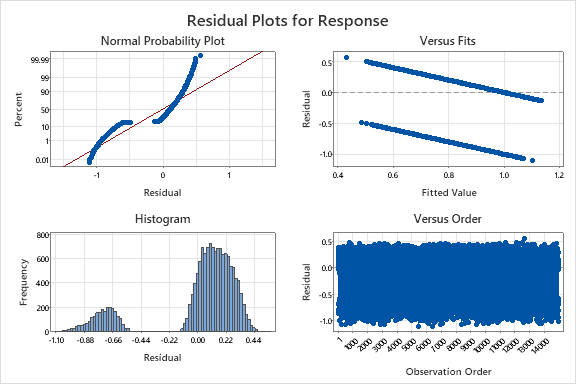
When I fit the original dataset into regression model with Minitab, I get attached result for residuals. It doesn't look normal. Does it mean there is high correlation or the dataset in have nonlinear response and predictors? How should I approach this? What would be my strategy if I use in Python, Minitab, and R. Explaining it in all softwares are appraciated if possible.
There are many ways to perform regression, you didn't specify what form of regression you attempted.
I assume you meant linear regression; but I suppose you should try logistic regression.
Thank you for the input. Yes, I think the intend was to find a dataset that I can fit into linear regression model which the one I provided a link is not really a good candidate (there is categorical predictor which I think messes up). I'll try to find a dataset that suits linear regression and work from there.
In general, when I have a new dataset, am I supposed to check its normality and do transformations accordingly or do I simply check collinearity and eliminate highly collinear predictors as part of pre-processing?