Hi !
I have summarized the problem below, using reprex, which somewhere lies between pivot and separate from the tidy-verse.
Will appreciate help. Thanks !
# Make sure to include library calls for all the libraries that you are using in your example
library(tidyverse)
# Remember to include the sample data that you have generated
structure(list(customer = c("Alpha", "Beta"), reqts = c("soap, shampoo",
"shampoo, detergent, sanitizer")), class = c("spec_tbl_df", "tbl_df",
"tbl", "data.frame"), row.names = c(NA, -2L), spec = structure(list(
cols = list(customer = structure(list(), class = c("collector_character",
"collector")), reqts = structure(list(), class = c("collector_character",
"collector"))), default = structure(list(), class = c("collector_guess",
"collector")), skip = 1L), class = "col_spec"))
# Narrow down your code to just the problematic part.
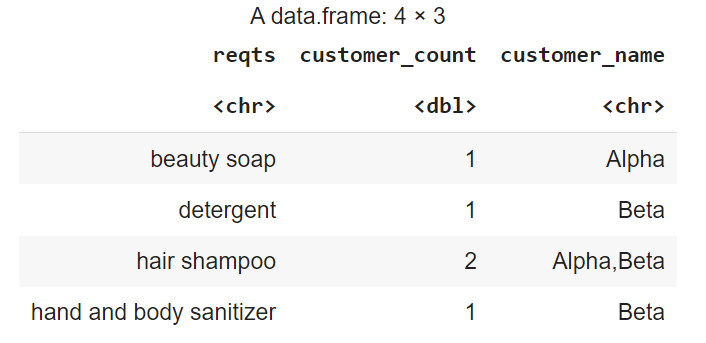
## Tried pivot_wider and separate
## but unable to produce the desired output as follows
## reqts customer_count
## soap 1
## shampoo 2
## detergent 1
## sanitizer 1