Motivation
I'm working on a project where I receive .docx files which I parse and then reconstruct in a parameterised .Rmd file. The .docx file contains many tables, and the contents of these tables varies considerably between the template files. This makes parsing them difficult because in some reports the Pandoc simple_tables extension is used, whereas in others grid_tables is required.
The question
There's a fully working repo here that demonstrates the issue, but I'll also include a reprex directly in this question below.
Let's download the .docx file to our working directory with {here}
library("here")
download.file("https://github.com/charliejhadley/pandoc-convert-table-types/raw/main/Example%20Word%20Report.docx",
here("word-doc.docx"))
The screenshot below shows there are two tables in the document
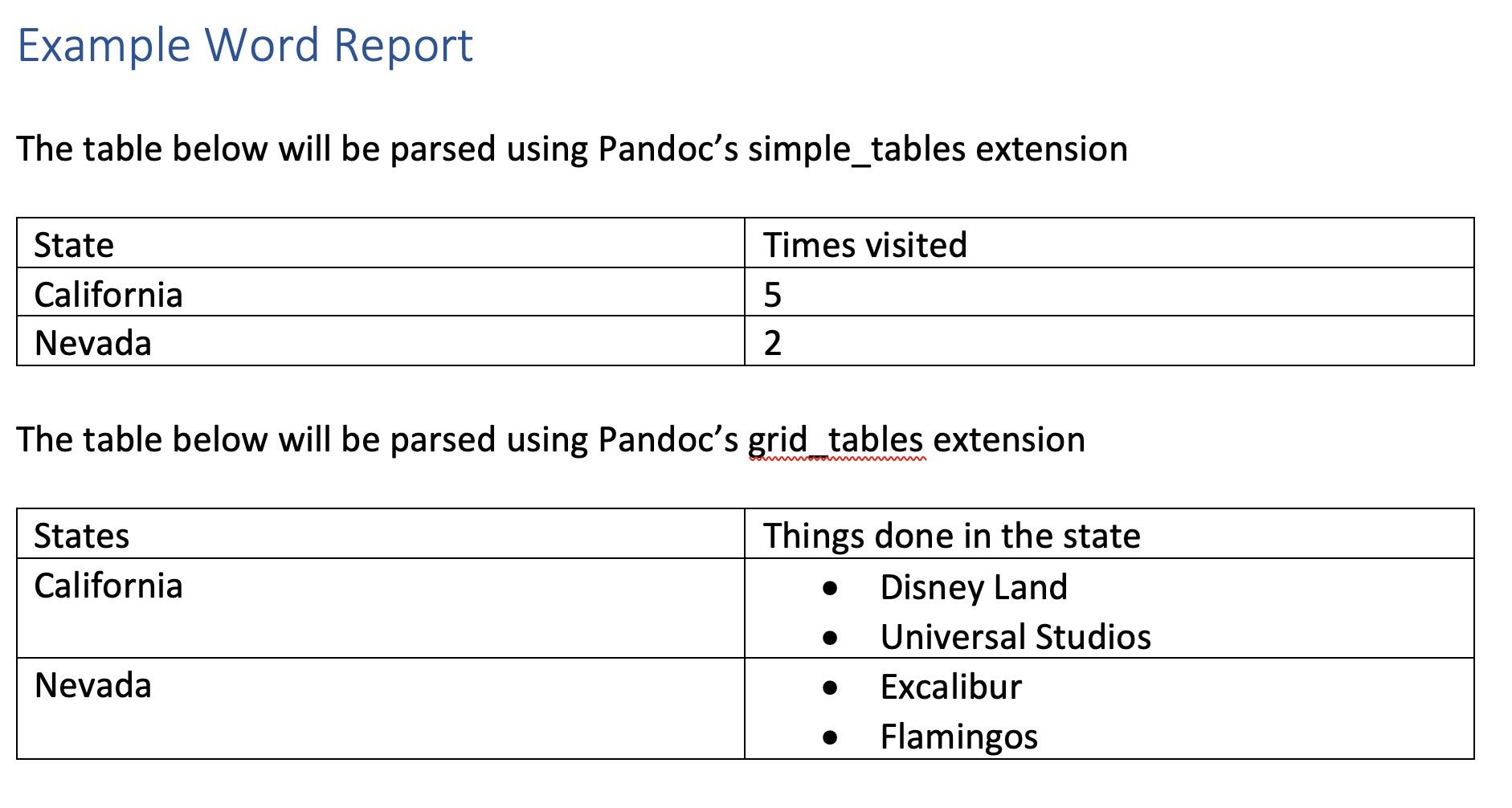
I use rmarkdown::pandoc_convert() to convert the .docx to a markdown file
rmarkdown::pandoc_convert(
input = here("word-doc.docx"),
to = "markdown",
output = here("Example Word Report.md")
)
But as you can see, each table is in a different format:
readLines(here("Example Word Report.md"))
#> [1] "# Example Word Report"
#> [2] ""
#> [3] "The table below will be parsed using Pandoc's simple_tables extension"
#> [4] ""
#> [5] " State Times visited"
#> [6] " ------------ ---------------"
#> [7] " California 5"
#> [8] " Nevada 2"
#> [9] ""
#> [10] "The table below will be parsed using Pandoc's grid_tables extension"
#> [11] ""
#> [12] "+------------+--------------------------+"
#> [13] "| States | Things done in the state |"
#> [14] "+============+==========================+"
#> [15] "| California | - Disney Land |"
#> [16] "| | |"
#> [17] "| | - Universal Studios |"
#> [18] "+------------+--------------------------+"
#> [19] "| Nevada | - Excalibur |"
#> [20] "| | |"
#> [21] "| | - Flamingos |"
#> [22] "+------------+--------------------------+"
How can I tell rmardown::pandoc_table() to always use the grid_tables extension or what alternative approaches are there to end up with a .md file with only grid_tables?
