Hi,
How about this:
library(stringr)
library(dplyr)
library(purrr)
#This should be the same as your csv file when read
myData = data.frame(
stringsAsFactors = FALSE,
ID = c(1L,2L,3L,4L,5L,6L,7L,8L,
9L,10L,11L,12L,13L,14L,15L,16L,17L,18L,19L,
20L,21L,22L,23L,24L),
payload = c("{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"10,65538,244,10,11,13,18\",\"last_counters\":\"10,3,244,10,11,13,18\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}","{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"13908,13105,13876,13414,13880,13876,13873,13364,13413,14137,13112,14137,14133,13107,13876,13366,13107,13105,14129,12897,13366,13365,13413,13619,13618,13625,13616,13620,13414,13410,13621,13113,0,13361,13362,14130,13921,13365,13107\"}",
"{\"counters\":\"13868,13105,13876,13414,13880,13876,13873,13364,13413,14137,13112,14137,14133,13107,13876,13366,13107,13105,14129,12897,13366,13365,13413,13619,13618,13625,13616,13620,13414,13410,13621,13113,0,13622,13366,13625,13365,14136,13366\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"12905,14391,25138,78130,13366,12851,77874,78130,13363,13874,13620,25908,13108,12853,14645,77876,13365,26165,90675,13620,14645,91186,79926,77874,12595,12598,13365,25142,13878,14389,14643,25910,0,14133,13877,12343,13110,12852,25136\",\"last_counters\":\"0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}","{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"\",\"last_counters\":\"\"}",
"{\"counters\":\"13925,13105,13876,13414,13880,13876,13873,13364,13413,14137,13112,14137,14133,13107,13876,13366,13107,13105,14129,12897,13366,13365,13413,13619,13618,13625,13616,13620,13414,13410,13621,13113,0,13412,13362,13873,13880,13366,14179\"}",
"{\"counters\":\"12902,14391,25138,12595,13366,12851,12339,12595,13363,13874,13620,25908,13108,12853,14645,12341,13365,26165,25140,13620,14645,25651,13110,13109,25908,12853,14390,14390,25142,25398,14134,24885,0,14131,12339,13623,25908,25654,13156\"}",
"{\"counters\":\"13826,13105,13876,13414,13880,13876,13873,13364,13413,14137,13112,14137,14133,13107,13876,13366,13107,13105,14129,12897,13366,13365,13413,13619,13618,13625,13616,13620,13414,13410,13621,13113,0,14179,13880,13154,14134,13366,13367\"}",
"{\"counters\":\"13919,13105,13876,13414,13880,13876,13873,13364,13413,14137,13112,14137,14133,13107,13876,13366,13107,13105,14129,12897,13366,13365,13413,13619,13618,13625,13616,13620,13414,13410,13621,13113,0,13365,13107,13112,14135,13625,13364\"}",
"{\"counters\":\"0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0\"}")
)
#Extract the values from the JSON string per line
extractData = map(myData$payload, function(x){
data = str_match_all(x, ":\"([\\d,\\.]+)\"")[[1]][,2]
#Sometimes there is no last_counters, in that case return NA for that
if(length(data) == 2){
list(
max(str_split(data[1], ",") %>% unlist %>% as.integer()),
max(str_split(data[2], ",") %>% unlist %>% as.integer())
)
} else {
list(
max(str_split(data[1], ",") %>% unlist %>% as.integer()),
NA
)
}
})
#Build a data frame with the IDs and the extracted data
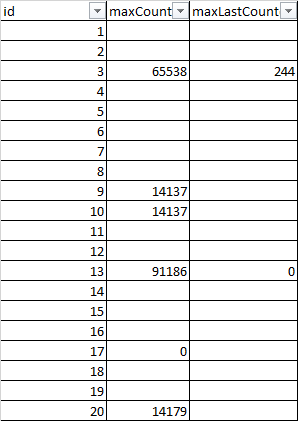
myData = data.frame(ID = myData$ID,
maxCounter = sapply(extractData, "[[", 1),
maxLastCounter = sapply(extractData, "[[", 2))
There are a LOT of NAs in this data frame, so I'm not sure what you want to use it for but here it is anyway 
Hope this helps,
PJ