I could not get a parallel job to run properly when submitted to a compute cluster via the RStudio Terminal. After going down a rabbit hole for a month, I finally tried submitting the job via the MobaXterm SSH client and the job ran flawlessly. Was I wrong to assume that the terminal establishes a SSH connection or is this a bug? Other posts suggest it's an authentication issue when multiple cores are requested.
First of all it is great that the parallel job works if you run it via SSH connection (MobaXterm).
The reasons why it does not work in an RStudio Terminal can be manifold. Would you mind sharing a bit more information how you are using parallel computing with R ? Are you using any of the future's, batchtools, clustermq, doMC, doMPI, doParallel, etc... ?
If you run on the RStudio Terminal, what error message do you get or what behaviour do you see that makes you think something is wrong ?
Lastly, is your RStudio Session running on the compute cluster or is this a separate environment ? If it is separate, are the servers where RStudio runs configured to submit jobs to the cluster ?
Here is my setup.
R version 3.6.1
RStudio 1.1.383
library(plyr)
library(doParallel)
#Setup parallel backend to use many processors
cores <- as.integer(Sys.getenv("SLURM_CPUS_PER_TASK"))
registerDoParallel(cores)
The plyr::mlply function seems to be the issue in:
flatten_chr(mlply(input, .fun = which_closest2, table=WWIS, .parallel = TRUE, .progress = "text"))
Typical error is that a variable does not exist when I try to execute a downstream manipulation.
When I configure the code to run serially, it works flawlessly during testing and when I submit the job to the SLURM job manager to run on the cluster via the RStudio terminal. However, when I ask the job to run in parallel, the job fails.
Here is my BASH Script:
#!/bin/bash
#SBATCH -c 10
#SBATCH --mem=24G
#SBATCH -t 2-0:0:0
#SBATCH --mail-type=ALL
#SBATCH --mail-user=
module load nixpkgs/16.09 gcc/7.3.0
module load r/3.6.1
Rscript join_all_2021_nearest_neighbour.R
Thanks for your detailed reply. It seems you are on the right track.
The missing bit: By going from single core to multicore you need to be aware that one R process is started on each core. Those processes are independent of each other and do not share the same memory and hence do not have access to the same functions let alone variables.
A generic way now would be to use parallel::clusterExport() and export the missing variables, like this:
library(doParallel)
cores <- as.integer(Sys.getenv("SLURM_CPUS_PER_TASK"))
mycluster = makeCluster(cores)
registerDoParallel(mycluster)
...
# var1 is a variable that cannot be found
var1<-1
clusterExport(mycluster,"var1")
...
flatten_chr(mlply(input, .fun = which_closest2, table=WWIS, .parallel = TRUE, .progress = "text"))
plyr however also allows for the .paropts parameter which then can contain any option you would use in foreach for parallel processing. Exporting a variable (or package) now becomes integrated in the plyr command via
flatten_chr(mlply(input, .fun = which_closest2, table=WWIS, .parallel = TRUE, .progress = "text",.paropts = list(.exports = c("var1", "var2", ...), .packages = c("package1", "package2", ...)))
So, to summarize: clusterExport is probably more explicit, specifying .paropts is more integrated.
References:
On a related note: The approach with writing bash scripts to submit to the HPC cluster is perfectly fine.
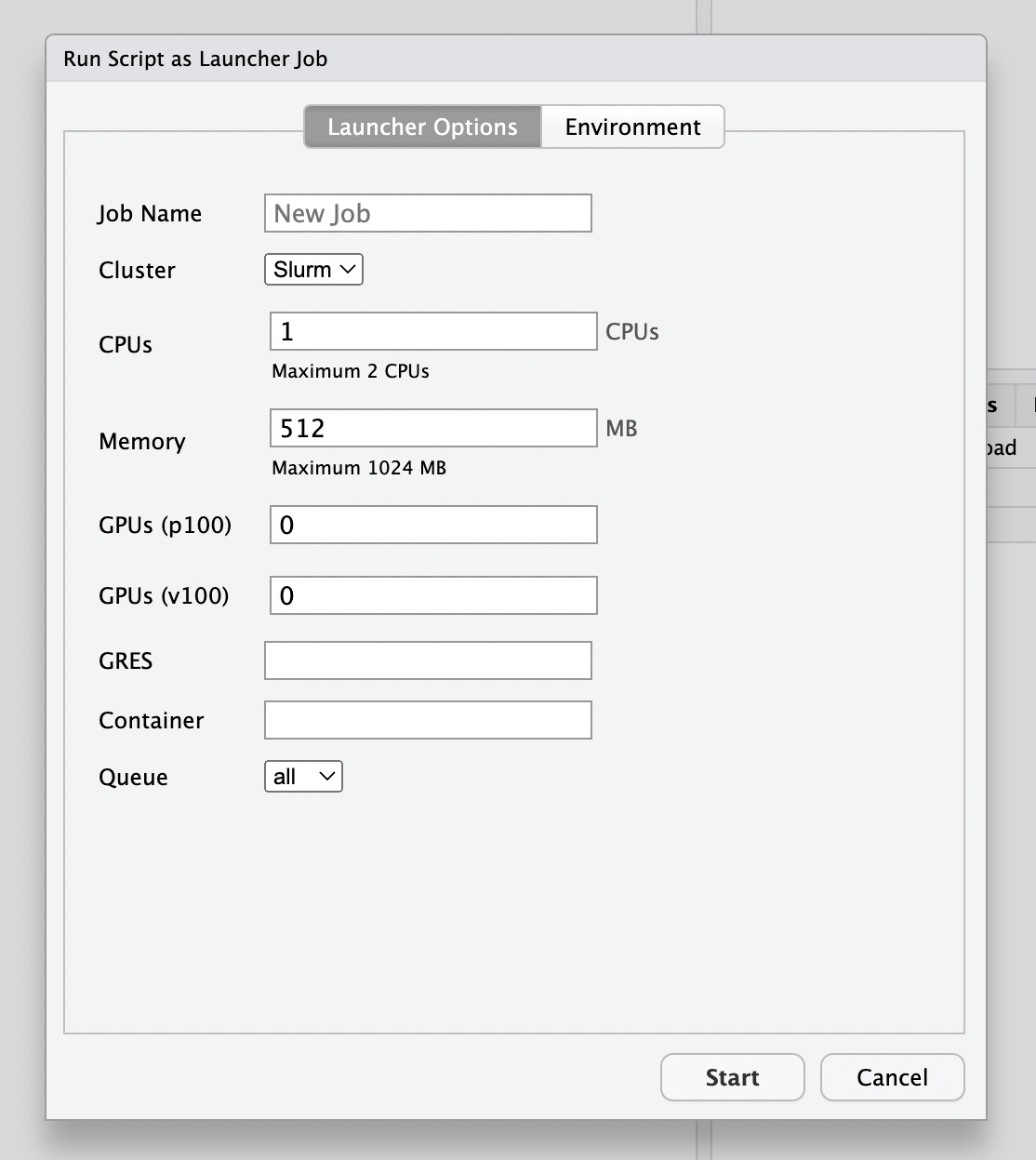
For deeper integration between RSW and SLURM you may be aware that RSW also features the Launcher Jobs for both SLURM and Kubernetes as backends. In your case you could use the SLURM launcher to run the R Session directly on the HPC and launch a separate so-called "Launcher job" from there that would automagically submit your R script to the SLURM queue without writing a script. You then can trace progress all from within the RSW IDE.
Thank you. I'll give your suggestion a try.
Great info and thanks for sharing. I believe our cluster's RStudio is the freeware version and I don't believe they have this "launcher" option available. I also note the 2 CPU and 1024 MB RAM options, which is limiting unless of course the admin can configure these settings higher.
Thanks for your feedback - hope you will get the parallel code running soon.
And yes, ..
- if your RStudio is the freeware/OpenSource one, you will not have the launcher capabilities unfortunately
- the limits are configurable to whatever you or your user base needs subject to hardware availability.
Made some progress. Now it looks like I need to "export" my custom function ("which_closest2") to each core via the .paropts argument. How is this achieved?
Glad to see you are making progress.
Exporting functions should work the same as exporting variables, simply use
.paropts = list(.exports = c("var1", "var2", ...,"fun1", "fun2", ...,) .packages = c("package1", "package2", ...))
or add the function name in double quotes to.exports.
Hmm?? Tried it the way you suggested and also like this (just to try) and no luck.
flatten_chr(mlply(input, .fun = which_closest2, table=WWIS, .parallel = TRUE, .progress = "text", .packages = c("plyr" , "doParallel", "multidplyr" , "stringr", "tidyverse") , .export = c("which_closest", "which_closest2")))
SLURM Output:
Error in do.ply(i) : task 1 failed - "object 'which_closest2' not found"
Calls: flatten_chr ... mlply -> alply -> llply -> ->
In addition: Warning messages:
1: : ... may be used in an incorrect context: ‘.fun(piece, ...)’
2: : ... may be used in an incorrect context: ‘.fun(piece, ...)’
Execution halted
Ok, something fishy going on here. Below you will find an example both for native foreach and mlply(that uses foreach).
The strange thing is that the .export in mlply does not seem to work. Will get in touch with the developers to see if there is a misunderstanding on my side or if this is a genuine bug.
If you use clusterExport instead of .export, it will work as expected.
I would appreciate if you could give the clusterExport route a try.
Below is an example for both foreach and mlply with annotations which part is working and which one does produce an error.
library(doParallel)
library(plyr)
cores <- 2
foreachcl = makeCluster(cores)
registerDoParallel(foreachcl)
myfx <- function(x) {
x*x
}
func1 <- function(x) {
foreach(i = 1:2) %dopar% {
Sys.sleep(.1)
myfx(i)
}
}
func2 <- function(x) {
foreach(i = 1:2, .export = c("myfx")) %dopar% {
Sys.sleep(.1)
myfx(i)
}
}
# Basic test of foreach
## func1 will fail
func1()
## func2 will work due to .export in foreach loop
func2()
## func1 work now due to clusterExport()
clusterExport(foreachcl,list("myfx"))
func1()
stopCluster(foreachcl)
# Going plyr
plyrcl = makeCluster(cores)
registerDoParallel(plyrcl)
## mlply will fail with "could not find function "myfx"
mlply(.data=cbind(1:2), .fun = func1)
## mlply will work due to .export in foreach loop
mlply(.data=cbind(1:2), .fun = func2)
## mlply will fail with "could not find function "myfx"
mlply(.data=cbind(1:2), .fun = func1,.paropts=list(.export="myfx"))
## mlply finally works due to clusterExport()
clusterExport(plyrcl,c("myfx"))
mlply(.data=cbind(1:2), .fun = func1)
stopCluster(plyrcl)
This topic was automatically closed 21 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.