since you haven't provided any example code or data we can only sort of guess at how to help you. Plus what you do provide is riddled with typos. For example, "ploy1" is not a valid detrending method.
But I can provide some thoughts that might be helpful:
You are starting with a "boil the ocean" approach of just coding up the full ideal implementation you'd like. This almost never works with data at scale. A better design pattern is to build up your model with small amounts of data and then test how that works as the data goes.
The question I have is how does the DFA function work as the size of the data grows. My secondary question is the impact of your choice for scale.max. To profile this function I made up some dummy data and just ran all combinations of n (data records) and scale_factor (default is 2, you used 1)
library(fractal)
library(tidyverse)
test_speed <- function(n, scale_factor) {
x <- rnorm(n)
start_time <- Sys.time()
DFA.walk <-
DFA(
x,
detrend = "poly1",
sum.order = 0,
overlap = 0,
scale.max = trunc(length(x) / scale_factor),
scale.min = NULL,
scale.ratio = 2,
verbose = FALSE
)
return(as.numeric(Sys.time() - start_time))
}
runs <- expand.grid(n = c(1e4, 2e4, 3e4, 4e4, 5e4, 6e4, 7e4, 8e4, 9e4, 1e5),
scale_factor = c(1, 2))
runs_timed <- runs %>%
rowwise %>%
mutate(run_time = test_speed(n, scale_factor)) %>%
mutate(scale_factor = factor(scale_factor))
ggplot(runs_timed) +
aes(x = n, y = run_time, colour = scale_factor) +
geom_point(size = 3L) +
theme_minimal()
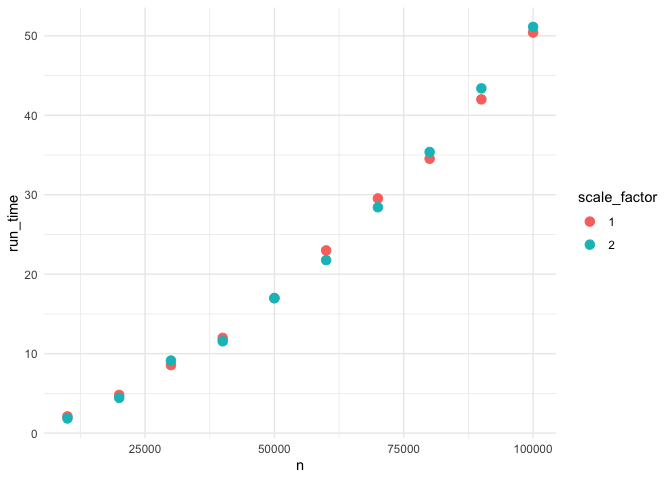
Created on 2019-08-19 by the reprex package (v0.3.0)
So from the graph we can tell that run time is increasing exponentially with data size. But the scale_factor has very little effect.
Let's build a model and extrapolate out to predict how long our model would expect 1.6m records to take:
We'll use a simple OLS regression but take the log of the run_time:
m <- lm(data=runs_timed, log(run_time) ~ n)
summary(m)
#>
#> Call:
#> lm(formula = log(run_time) ~ n, data = runs_timed)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.55434 -0.12559 0.09645 0.17991 0.27338
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.056e+00 1.207e-01 8.742 6.77e-08 ***
#> n 3.204e-05 1.946e-06 16.467 2.68e-12 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.25 on 18 degrees of freedom
#> Multiple R-squared: 0.9378, Adjusted R-squared: 0.9343
#> F-statistic: 271.2 on 1 and 18 DF, p-value: 2.678e-12```
That's not too bad of a regression fit. Let's use that model to extrapolate run time for a single model run on 1.8m records. This is, of course, based on my hardware (2018 Mac Book Pro), using totally random data since we don't have any actual data. Your results will be different:
## calc the expected run time of 1.8m (in hours)
exp(predict(m, data.frame(n=1.6e6)) ) / 60 / 60
#> 1
#> 1.473304e+19
So if that's correct, then it will take only a couple of years to run. Clearly in your example you tested and this does not take years, but rather takes days. So our model is likely off. But you can tell it will take a while. And this is largely an example of how to figure out how to think about your computational problem.
If you are going to "bolt on" parallelization in R, the way it's done is to split individual runs where each run takes place on a different machine or processor. This won't help here because a single run takes a long time. With this type of problem you need to rethink what you're doing.
Since I don't know your domain I can't guess which approach is going to make sense, but you could consider the following ideas:
- reduce the density of time sampling from 5 min to something much larger (if the process is slow moving this makes a lot of sense)
- find an algorithm that supports parallelization
- you could explore doing DFA on Hadooop or Spark parallel backends.
- rethink whether what you are doing makes sense at all
Good luck. If you run into specific challenges, feel free to drop back in with a more reproducible example.