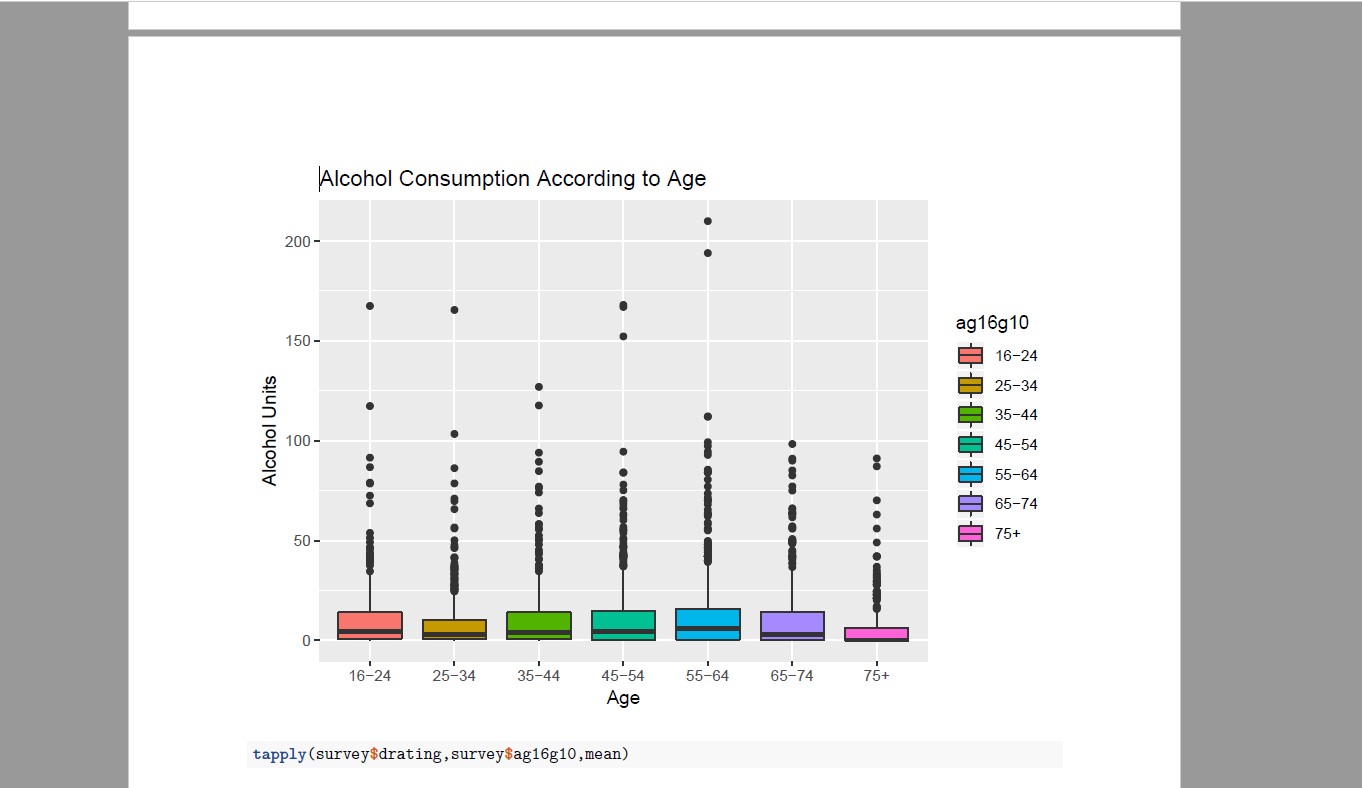
I have failed miserably in a very specific part of my data analysis. It is a project for a Data Analysis Course, and everything went well until a very specific problem came up: Outliers. All of my box plots have some extreme values. The y value is total alcohol units per week, and the x value is Age 16+ in Ten year bands. The dataset which I am using is the 2016 Scottish Heath Survey.
I wish to remove the outliers, but despite my exhaustive search nothing has come up. I do not wish to make them invisible, but rather to find out these extreme values and then remove them from the visualisations. I understand that this question may have been answered before, and the solution could potentially be simple, but I am asking due to lack of experience.
I thank you in advance for your time and help.
Here is the code:
First I Load the Data
survey<-read.delim("C:/Alcohol 2/shes16i_archive_v1.tab")
Then I convert the Age 16 + variable into a factor
survey$ag16g10<-factor(survey$ag16g10,levels=1:7,labels=c("16-24","25-34","35-44","45-54","55-64","65-74", "75+"))
Then the boxplot
agebox<-survey%>%filter(drating>=0)%>%ggplot(aes(x=ag16g10,y=drating,fill=ag16g10))+geom_boxplot()+labs((title ="Alcohol Consumption According to Age",x="Age",y="Alcohol Units" )
After all that I have a boxplot which has some outliers and I wish to remove them. So, how can I find the extreme values within the variables and then remove them from the box plot?
Best regards,
M.