I have read through the documentation for oneway model in the lattice package, but I am unclear as to whether the residuals generated are based on the full data set (pooled) or the grouped (by factor) data.
Does anyone have insight on this? Thanks!!
I haven't used the oneway function before, but we can compare it with the same model generated with aov (ANOVA) and lm (linear regression) and see that they're all reporting exactly the same residuals and fitted values and also that the residuals are the difference between each observation and the model fit for that observation. Since we only have Species in the model, the model fit is always the same for a given level of Species.
library(tidyverse)
library(lattice)
# Models
f = formula(Sepal.Length ~ Species)
m = list(oneway = oneway(f, data=iris),
aov = aov(f, data=iris),
lm = lm(f, data=iris))
# Extract residuals and fitted values
d = map_df(m, ~data.frame(fitted=fitted(.x), resid=resid(.x)), .id="model")
ggplot(d %>% group_by_all() %>% summarise(),
aes(fitted, resid, colour=model, size=model)) +
geom_point() +
scale_colour_viridis_d() +
scale_size_manual(values=c(4,3,2)) +
theme_classic()
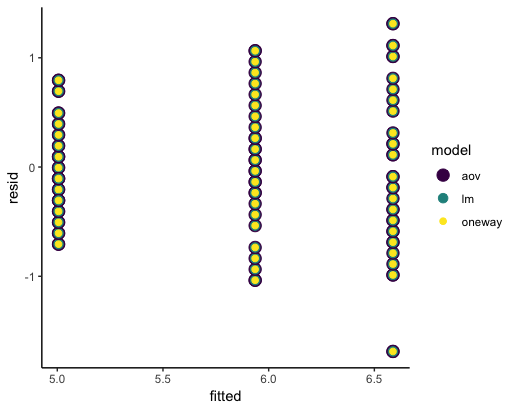
Direct check for all three models that reported residuals are equal to Sepal.Length (the observations) minus the fitted values from the model:
d %>%
mutate(Sepal.Length = rep(iris$Sepal.Length, 3),
check = all.equal(Sepal.Length - fitted, resid)) %>%
group_by(model, check) %>%
tally
model check n 1 aov TRUE 150 2 lm TRUE 150 3 oneway TRUE 150
2 Likes