Hello,
I need some help, visualizing the variable levels:
df <- data.frame(x = 1:6,
I have 9 millions of genres, I need to have a sapply or list or other, that shows the levels of genres column variable.
What function can show a result like this?
Output:
genres
I tried with levels(), group_by (), separate() and others... and results like this:
levels(df)
df %>% select(genres) %>% separate_rows() %>% summarise(n = n())
Just numeric result, and not the name of the observations that has the column genre.
Thanks!! =)
The levels() function is to be applied on "factor" class variables, not entire data frames
library(dplyr)
df <- data.frame(x = 1:6,
movies = c("movie1", "movie2", "movie3", "movie4", "movie5", "movie6" ),
genres = c("Romance/Terror", "Action/Comedy", "Adventure/Action",
"Romance/Action", "Action/Fantasy", "Action/Drama"),
stringsAsFactors = FALSE)
df %>%
mutate(genres = as.factor(genres)) %>%
pull(genres) %>%
levels()
#> [1] "Action/Comedy" "Action/Drama" "Action/Fantasy" "Adventure/Action"
#> [5] "Romance/Action" "Romance/Terror"
The problem with this is that you are not using valid syntax, if I understand your intention correctly, it should be something like this:
library(dplyr)
library(tidyr)
df <- data.frame(x = 1:6,
movies = c("movie1", "movie2", "movie3", "movie4", "movie5", "movie6" ),
genres = c("Romance/Terror", "Action/Comedy", "Adventure/Action",
"Romance/Action", "Action/Fantasy", "Action/Drama"),
stringsAsFactors = FALSE)
df %>%
separate_rows(genres) %>%
distinct(genres)
#> # A tibble: 7 × 1
#> genres
#> <chr>
#> 1 Romance
#> 2 Terror
#> 3 Action
#> 4 Comedy
#> 5 Adventure
#> 6 Fantasy
#> 7 Drama
Created on 2022-08-17 by the reprex package (v2.0.1)
But without the /
And just an output like this:
genres
Without the / slash and just the words that are in the column without repeat.
Thank you very much my friend!
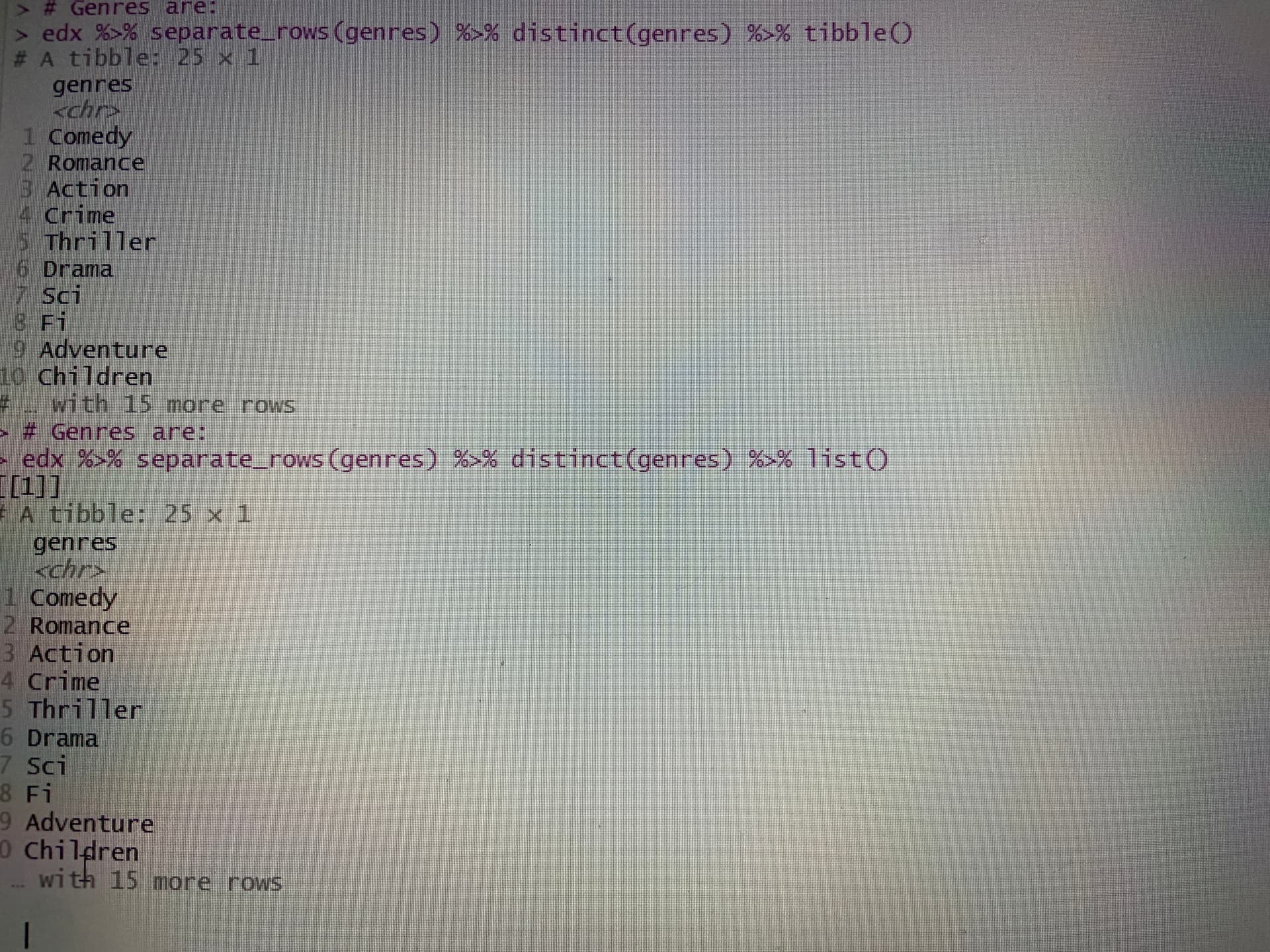
It shows me this output:
genres
1 Comedy
Now I have to find a function to pipe and visualize the others 15 more, because it’s necessary how many levels has that column in more than 9 millions of rows.
I’ll try with some functions, to see the others 15 rows.
Can you recommend something? (I tried with pipe tibble() and pipe list() but it shows the same message : “ #… with 15 more rows”.
Thanks again my friend!
If you only want to visualize them, use the data viewer pane (with the View() function).
df %>%
separate_rows(genres) %>%
distinct(genres) %>%
View()
Thank you very much Andres!
system
August 25, 2022, 1:59am
8
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.